

JUNE 2024 I Volume 45, Issue 2
Deep Learning for Autonomous Vehicles
June 2024
Volume 45 I Issue 2
IN THIS JOURNAL:
- Issue at a Glance
- Chairman’s Message
Conversations with Experts
- A T&E Career of Learning by Doing: A Conversation with Mr. Edward R Greer
- A Bourbon with Rusty: A Conversation with Russell L. Roberts
Values in T&E
- My T&E Career, The First 25 Years
- The Architecture Analogy in Test Planning: An example of the T&E value of 'Well-Planned'
- Values in Operational Testing
Technical Articles
- Digital Test and Evaluation: Validation of System Models as a Key Enabler
- Statistical Review of the Cyber Test Process
- The Robust Classical MTBF Test
Workforce of the Future
- Deep Learning for Autonomous Vehicles
- The K-D Tree as an Acceleration Structure in Dynamic, Three-Dimensional Ionospheric Modeling
- Optimization Engine to Enable Edge Deployment of Deep Learning Models
News
- Association News
- Chapter News
- Corporate Member News
Deep Learning for Autonomous Vehicles
Joe Pappas
HPC Internship Program, DoD High Performance Computing Modernization Program,
Aberdeen Proving Ground, MD 21005
Billy Geerhart
Advanced Computing Branch, Army Research Laboratory,
Aberdeen Proving Ground, MD 21005
Peng Wang, Ph.D.
Advanced Computing Branch, Army Research Laboratory,
Aberdeen Proving Ground, MD 21005
Abstract
In the domain of unmanned ground vehicle (UGV) navigation, efficient computer vision algorithms for resource-constrained devices are crucial. Virtuoso3, an adaptive video object detection framework, is among the first to jointly optimize for accuracy, latency, and energy efficiency; however, there are limitations in the classes that the baseline model can detect. Our objective was to enhance Virtuoso’s detection capabilities for classes we are interested in and deploy the algorithm with the ARL UGV software stack. First, we compare the baseline Virtuoso to an engineered ‘static’ version of Virtuoso to highlight the deficits of non-adaptive systems in high-resource contention environments. Then we fine-tuned Virtuoso’s detection backbones using HPC clusters. Finally, we validate the updated model with gathered real-world UGV perception test data showing a successful integration of Virtuoso with the software stack on the UGV. This work underscores the utility of adaptive frameworks leading to a harmonized system that can adapt the algorithms to UGVs hardware constraints as well as the deployed software stack while still maintaining real-time performance.
Keywords: Unmanned ground vehicle, computer vision, deep learning, object detection
Introduction
Perception algorithms are an essential facet of autonomous driving. Perception algorithms can include object detection and object tracking, semantic segmentation, and LiDAR point cloud interpolation. Figure 1 provides an outline for how these perception algorithms are deployed into the existing software stack. First, we load the model with pre-trained weights and fine-tune the perception algorithm using high performance computers (HPCs). Then, we use Robot Operating System (ROS) bag data collected directly from the UGV and perception code stack to test the output model. (Bags are the primary mechanism in ROS for data logging.) In this test, the image gets fed through the improved detection model, and we can observe the objects that detected in the scene. By improving the detection model deployed on the UGV, the UGV can better identify its surroundings, which allows it to make better navigation decisions.
Once multiple perceptions are deployed in the software stack, these algorithms must then work together within a holistic framework to achieve the goals associated with autonomous navigation. This section reviews some important concepts that are included in this holistic framework for autonomous driving, particularly focusing on video object detection, the implementation and implications of the Robot Operating System, and the importance and challenges of embedded GPUs, especially in the context of resource contention. Finally, we demonstrate the need for an adaptive framework by showing an empirical analysis of adaptive vs non-adaptive systems.
Embedded GPUs and Resource Contention
As edge devices increasingly demand real-time processing, the integration of embedded GPUs has gained prominence. Unlike standalone GPUs, embedded GPUs are directly incorporated into the device, facilitating the execution of multiple machine learning algorithms simultaneously. However, this concurrent operation leads to challenges like resource contention, where simultaneous tasks vie for the same GPU resources. Such contention can critically impact autonomous driving systems, as it might induce delays or cause algorithms to operate at suboptimal speeds.
Computer Vision in Autonomous Driving
Computer vision techniques such as object detection, semantic segmentation, and LiDAR point cloud segmentation have played pivotal roles in autonomous driving research. The combination of these algorithms are the key tools in autonomous driving tasks, such as barrier detection, path planning, and cost map analysis. In this work, two object detection architectures are explored, EfficientDet2 and YOLO1. EfficientDet uses two stages to perform object detection: a region proposal stage, and a classification stage. On the other hand, YOLO performs object detection in a single stage of inference. Typically, single shot detectors are faster than multistage detectors, but at a cost of accuracy.
Video Object Detection using Virtuoso
The ability of an autonomous vehicle to detect and recognize objects in a continuous video stream is crucial. Video object detection can be thought of as an extension of image object detection, where the video is treated as a series of images, and object detection is performed on each image sequentially. One way to improve latency for video object detection is to understand the time dimension of subsequent images, and that consecutive images will likely have very little difference between them. Therefore, you might be able to interpolate between images without having to run a slow detection algorithm on every image. For video object detection, the typical latency requirement is to be able to process at least 30 frames per second. Virtuoso3 is an energy and latency aware framework for performing video object detection on typically resource constrained devices. Virtuoso can detect when the GPU is under contention and chooses among benchmarked algorithms to keep latency below a specified threshold while keeping accuracy as high as possible.
Adaptive Framework Necessity
To underscore the need of an adaptive framework, we began with an empirical comparison between the adaptive capabilities of the baseline Virtuoso system and a deliberately engineered static version of the same. In this static iteration of Virtuoso, settings remain immutable, implying that in instances of heightened contention, configurations remain unchanged, leading to inevitable latency issues. We subjected both the adaptive and static versions of Virtuoso to two distinct operational environments: one characterized by low resource contention and another dominated by high resource contention. During the low contention phase, both variants of Virtuoso demonstrated commendable performance, adhering to the latency benchmarks required to process an average of 30 frames per second. Conversely, in the high contention environment, the static version’s vulnerabilities became apparent. Its performance sharply decreased to nearly half the stated latency standards. In stark contrast, the adaptive Virtuoso, while challenged, managed to hover just shy of the mandated latency thresholds, validating our proposition concerning the criticality of adaptability in dynamic autonomous driving scenarios.

Figure 2: Low resource contention setting. Static Virtuoso on the left, unchanged Virtuoso on the right.

Figure 3: High resource contention setting. Static Virtuoso on the left, unchanged Virtuoso on the right.
Autonomous driving hinges on advancements in computer vision, the evolution of object detection algorithms, and the robustness offered by platforms such as ROS. However, as the integration of embedded GPUs escalates, navigating and mitigating resource contention becomes pivotal to ensure the robustness of the autonomous driving system stack. To address this, our project endeavors to refine the autonomous driving systems utilized by ARL, with a specific focus on a resource-conscious framework. Notably, the foundational version of Virtuoso lacks detection on classes that are important to the ARL UGV system. Hence, the principal contributions of our project encompass:
1.Adapting the backbone detection model of Virtuoso by retraining it on a dataset tailored to our specific requirements.
2.Leveraging a high-performance computing training cluster in the cloud for model training.
3.Validating and deploying to the existing system via tests using ROS bag data sourced directly from the autonomous driving setup.
Materials and Methods
To produce and deploy an object detection backbone to be used in an adaptive framework, the following six objectives were defined:
1.Train a new model on GPU clusters.
2.Collect test data via the UGV perception system
3.Update the adaptive framework to use the newly trained models
4.Deploy to docker
5.Test with ROS bag data
6.Visualize with RViz
Model Training on GPU Cluster
To harness state-of-the-art object detection capabilities, we employed the YOLOv8 architecture. Two variants of the model, differing in size and complexity, were trained using the PASCAL VOC 2007 dataset: YOLOv8 Small and YOLOv8 XLarge. These two were chosen to be able to have two models that have noticeable differences in size and accuracy/latency tradeoffs. This training was conducted on a cluster of GPUs, ensuring efficient computation and allowing us to optimize model parameters cohesively.
Test data and Robot Operating System
ROS is a versatile framework tailored for crafting robot software. Central to this project are ROS’s modular architecture and its inter-node communication system. Systems within ROS are architected around independent units termed ‘nodes’. These nodes employ a publish/subscribe communication paradigm: one node, for instance, might disseminate sensor data, whereas another subscribes to this data for subsequent processing or decision-making. Given that nodes focus solely on the messages they send or receive, it’s feasible to generate test datasets known as ‘rosbags’, enabling isolated work on individual nodes without booting the entire system. This feature proves invaluable for our work, as it permits us to refine perception algorithms without necessitating the activation of the complete autonomous driving system. Our UGV equipped with an advanced perception system was deployed in real-world scenarios to generate a test rosbag. This rosbag effectively captures a sequence of messages, which would be pivotal for subsequent testing phases.
Update Adaptive Framework
Post training, the perception system was updated to utilize the newly trained YOLOv8 models. This integration aimed at enhancing the system’s object detection capabilities, making it more attuned to the specific challenges presented by our use-case scenarios.
Docker
Recognizing the significance of replicable and consistent testing environments, the updated system was deployed into a Docker container. This container was configured to emulate the UGV’s operating environment, ensuring that the tests would closely mirror real-world operations.
Testing with Rosbag Data
The Docker-contained system was then subjected to rigorous tests using the rosbag data generated earlier. The crux of this test was straightforward: if the system could flawlessly process and interpret the rosbag data, it would demonstrate the success of our model updates and integrations.
Visualization with RViz
To offer a tangible and visual representation of our system in action, we employed RViz, ROS’s 3D visualization tool. Through RViz, we could effectively visualize and monitor the perception system’s operations, tracking its object detection routines, and ensuring the seamless functioning of integrated components.
Our experimental design combined advanced training methodologies with real-world data collection and rigorous testing protocols. Each phase was carefully curated to further our project objectives, ensuring the development of a more adaptive, responsive, and reliable autonomous driving framework.
Results
Training results
Large models possess more parameters than smaller counterparts which directly affect training duration. Parameter count affects training time because of the extended computational time during backpropagation. Larger models take longer to reach convergence due to the heightened capacity to fit intricate data patterns. Below is a table demonstrating the difference in training time with real numbers during our training.
Table 1 Training results from training the two models. YOLOv8 s is a smaller model, and therefore takes shorter to train compared to YOLOv8 xl. Final mAP is the mAP 50-95 for all classes. The larger model has a higher mAP, but comes at the cost of slower inference. Our training method utilizes an early stopping protocol. If there is no noticeable improvement in the model for a given number of epochs, then we stop training. This is why there is a lower number of epochs for the small model compared to the xl model.
| Model | Size (number of parameters) | Time to train (hrs) | Number of Epochs | Final mAP |
| YOLOv8 s | 11.1 M | 0.595 | 51 | 0.548 |
| YOLOv8 xl | 68.1 M | 1.898 | 100 | 0.569 |
The following figures demonstrate the results of fine tuning YOLOv8xl. When fine tuning, the accuracy metrics typically fall very fast and then improve. This is due to the model being pre-trained on a different dataset and learning the new dataset. You can see this in the kink at the start of the training iterations. Additional figures and results are provided in the appendix.
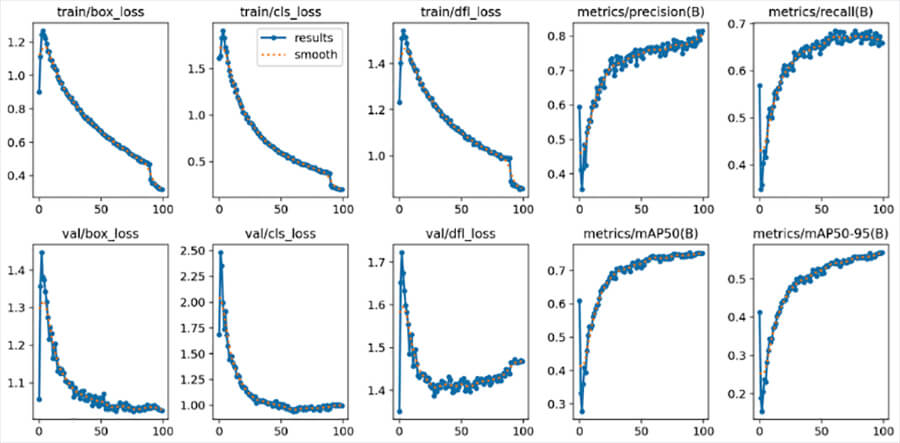
Figure 4: Result plots from fine tuning YOLOv8xl. There is bounding box loss, classification loss, and dual focus loss, which accounts for class imbalance in the dataset. Additionally, we provide mAP, precision, and recall.
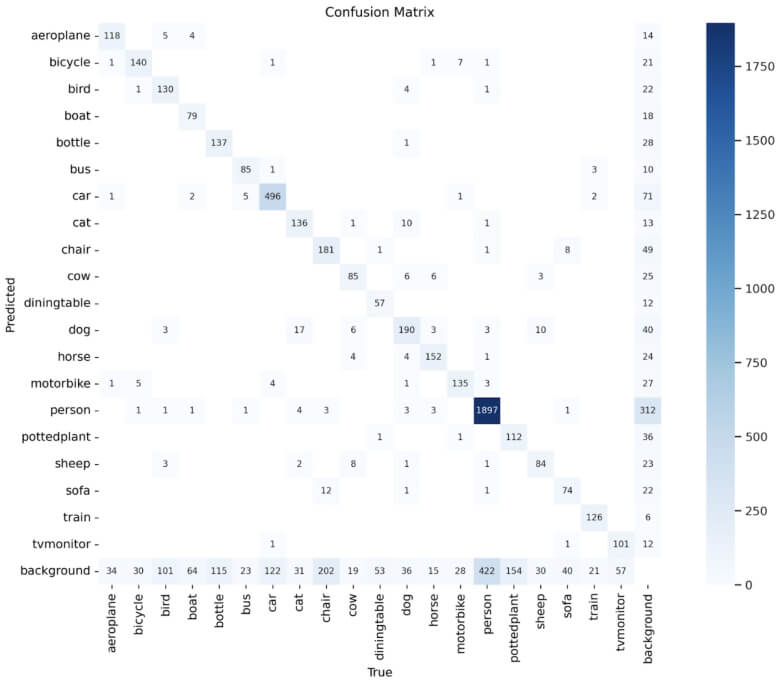
Figure 5: Confusion matrix for the classes in PASCAL VOC 2007 after fine tuning on YOLOv8s.
The following figures demonstrate the results of fine tuning YOLOv8s.
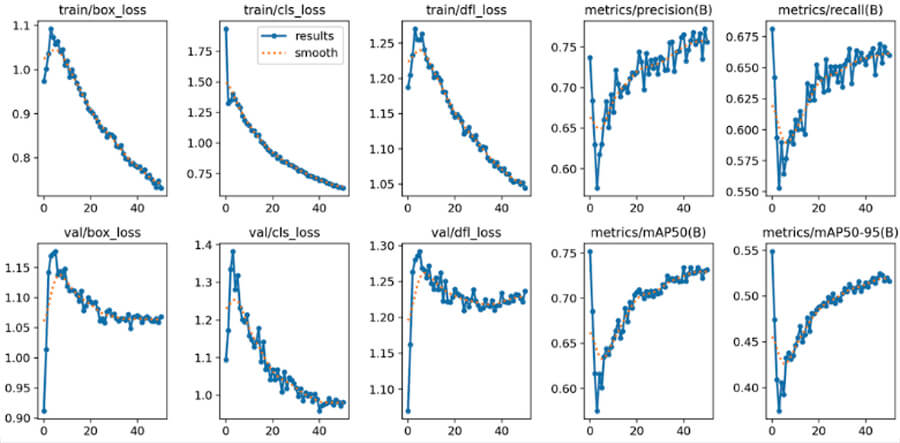
Figure 6: Result plots from fine tuning YOLOv8s. There is bounding box loss, classification loss, and dual focus loss, which accounts for class imbalance in the dataset. Additionally, we provide mAP, precision, and recall.
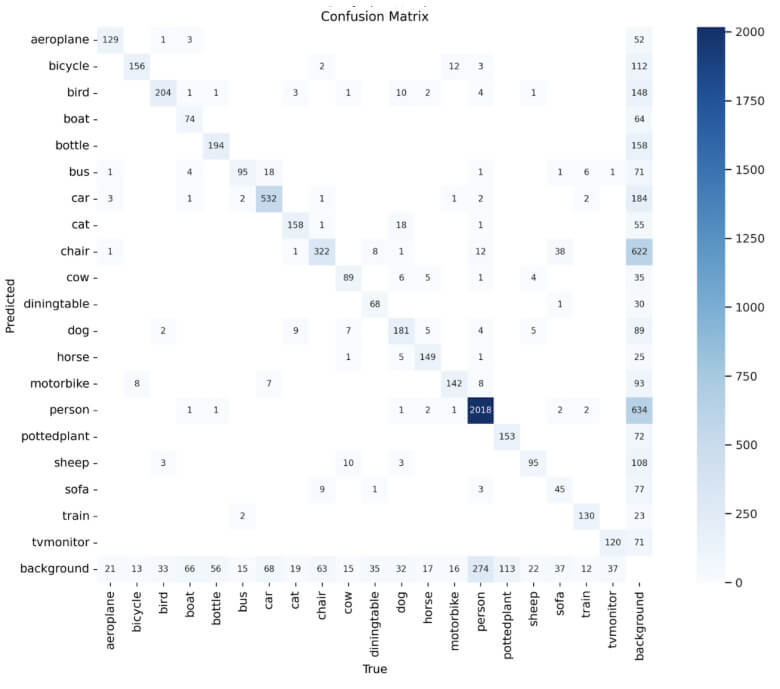
Figure 7: Confusion matrix for the classes in PASCAL VOC 2007 after fine tuning on YOLOv8s.
Figures 8 and 9 are test images pulled directly from the test rosbag data gathered from the UGV. As you can see, in Figure 8, the human on the left was not able to be detected by the object detector. In contrast, Figure 9 displays the output of the object detector post-fine-retraining.

Figure 8: Test image before retraining. The human on the left is not detected.

Figure 9: Test image after model retraining. Compared to the model without retraining, you can see that the human on the left is detected, whereas before it was not.
Conclusions
In the realm of autonomous driving, the foundational role of computer vision and perception algorithms as well as the infrastructure provided by platforms like ROS, cannot be understated. This paper illuminated the quintessential need for an adaptive framework, especially as we grapple with the integration of embedded GPUs in dynamic environments. Through empirical investigations, we compared the performance of adaptive and static versions of the Virtuoso framework under varying resource contentions, revealing the vulnerabilities of non-adaptive structures in high-contention scenarios. By harnessing GPU clusters, we refined our model’s performance by ensuring the model could detect the classes that are important to the ARL UGV system. Our use of a systematic approach, from data collection via UGV’s perception system to rigorous testing protocols, has reaffirmed the value of adaptability in autonomous systems, and left ARL with a system ready to deploy.
This concept of an adaptive framework can be extended for other perception algorithms. Subsequent endeavors could see the principles of adaptivity being infused into arenas like semantic segmentation and 3D LiDAR point cloud segmentation. Given that these algorithms are the collective bedrock of autonomous driving, an integrated adaptive approach becomes even more compelling. Such an approach would involve a cohesive system that dynamically recognizes and adjusts to the current significance each algorithm contributes to cost map generation during autonomous operations. This strategic interplay and the development of a truly responsive, interconnected adaptive system provides a fruitful direction for future research in this domain.
Impact of Summer Research Experience
The exposure to ROS in a mature autonomous driving setting was a key learning for me in this internship. I had never used ROS before, but seeing how ROS can be used to test algorithm improvements is something I plan to take back to my lab at Purdue for UAV and drone settings. By participating in this internship, I was able to see how a research lab works to contribute to a larger team where collaboration between teams becomes more important.
Acknowledgements
This work was supported by the mentorship of Dr. Peng Wang and the members of the ARL-RCAC lab, namely Billy Geerhart and David Alexander. Additionally, this work was supported in part by high-performance computer time and resources from the Department of Defense (DOD) High Performance Computing Modernization Program in collaboration with an appointment to the DOD Research Participation Program administered by the Oak Ridge Institute for Science and Education (ORISE) through an interagency agreement between the U.S. Department of Energy (DOE) and the DOD. ORISE is managed by ORAU under DOE contract number DE-SC0014664. All opinions expressed in this paper are the author’s and do not necessarily reflect the policies and views of DOD, DOE, or ORAU/ORISE.
Appendix
YOLOv8 small training results:
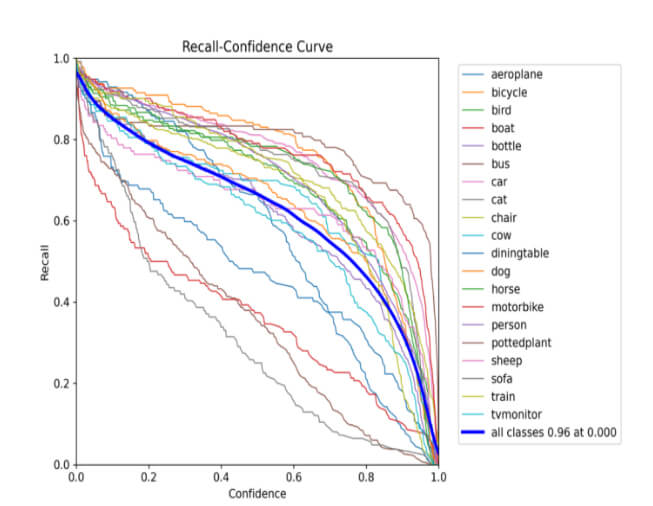
Figure 10: Recall-confidence curve for training the YOLOv8s model.
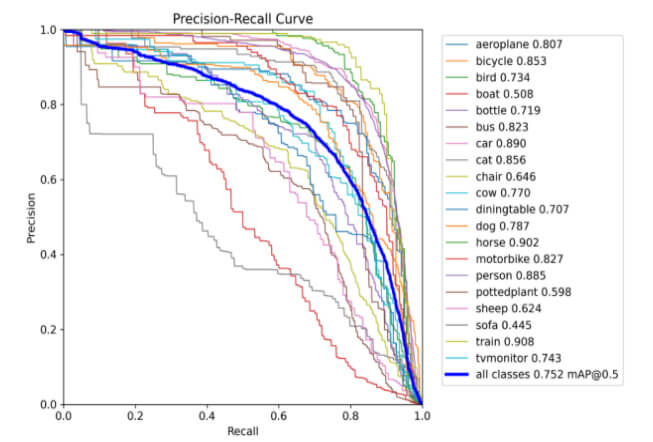
Figure 11: PR curve for training the YOLOv8s model.
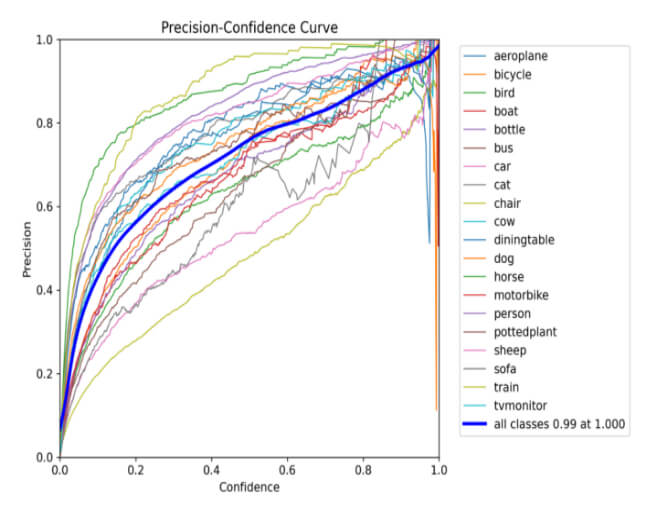
Figure 12: Precision-confidence curve for training the YOLOv8s model.
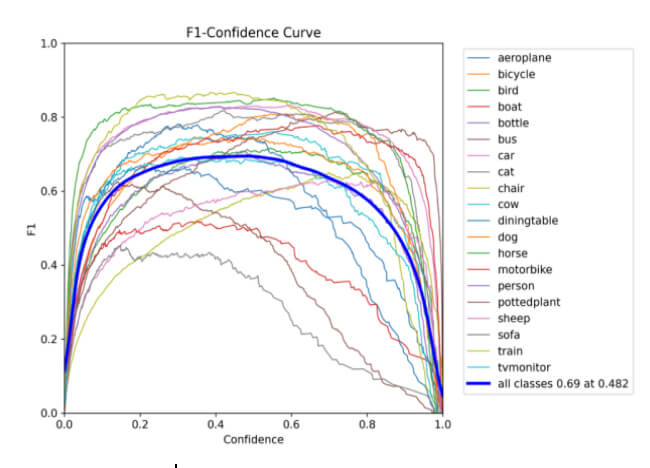
Figure 13: F1 curve for training the YOLOv8s model.
Figure 14: Recall-confidence curve for training the YOLOv8xl model.
Figure 15: PR curve for training the YOLOv8xl model.
Figure 16: Precision-confidence curve for training the YOLOv8s model.
 Figure 17: F1 curve for training the YOLOv8s model.
Figure 17: F1 curve for training the YOLOv8s model.
References
1.J. Redmon, S. Divvala, R. Girshick and A. Farhadi, “You Only Look Once: Unified, Real-Time Object Detection,” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016, pp. 779-788, doi: 10.1109/CVPR.2016.91.
2.M. Tan, R. Pang and Q. V. Le, “EfficientDet: Scalable and Efficient Object Detection,” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 2020, pp. 10778-10787, doi: 10.1109/CVPR42600.2020.01079.
3.Jayoung Lee, Pengcheng Wang, Ran Xu, Sarthak Jain, Venkat Dasari, Noah Weston, Yin Li, Saurabh Bagchi, and Somali Chaterji. 2023. Virtuoso: Energy- and Latency-aware Streamlining of Streaming Videos on Systems-on-Chips. ACM Trans. Des. Autom. Electron. Syst. 28, 3, Article 31 (May 2023), 32 pages. https://doi.org/10.1145/3564289
Author Biographies
JOSEPH PAPPAS graduated from Ohio State University with a degree in Computer Science with a focus in Artificial Intelligence and Machine Learning. He is currently pursuing a Master of Science degree at Purdue University in the school Agricultural and Biological Engineering with a focus on machine learning for Internet of Things, drones, and serverless computing. His research involves computer vision and detection algorithms for UAVs. The work done in this paper showcases the ability to run machine learning algorithms on resource constrained devices. These resource constraints can include energy and latency constraints, or in the case of agricultural fields, network bandwidth constraints. The work can be extended for use in any number of robotics systems where these constraints are always prevalent.
BILLY E GEERHART III is a computer scientist with the Army Research Laboratory. His research interests include adaptive computing, quantum computing, dark matter and energy in relation to fundamental physics.PENG WANG, Ph.D., is a research scientist at the U.S. Army Research Laboratory. He received an M.S. degree in electrical engineering from North Carolina State University, Raleigh, North Carolina in 2003, and Ph.D. degree in computer engineering from the University of Delaware, Newark, Delaware in 2009. His research interests include deep learning model optimization, edge computing, deep learning for blind signal classification, network optimization, system modeling and simulation, cognitive radio networks, and congestion control.
PENG WANG, Ph.D., is a research scientist at the U.S. Army Research Laboratory. He received an M.S. degree in electrical engineering from North Carolina State University, Raleigh, North Carolina in 2003, and Ph.D. degree in computer engineering from the University of Delaware, Newark, Delaware in 2009. His research interests include deep learning model optimization, edge computing, deep learning for blind signal classification, network optimization, system modeling and simulation, cognitive radio networks, and congestion control.
