

JUNE 2024 I Volume 45, Issue 2
The K-D Tree as an Acceleration Structure in Dynamic
June 2024
Volume 45 I Issue 2
IN THIS JOURNAL:
- Issue at a Glance
- Chairman’s Message
Conversations with Experts
- A T&E Career of Learning by Doing: A Conversation with Mr. Edward R Greer
- A Bourbon with Rusty: A Conversation with Russell L. Roberts
Values in T&E
- My T&E Career, The First 25 Years
- The Architecture Analogy in Test Planning: An example of the T&E value of 'Well-Planned'
- Values in Operational Testing
Technical Articles
- Digital Test and Evaluation: Validation of System Models as a Key Enabler
- Statistical Review of the Cyber Test Process
- The Robust Classical MTBF Test
Workforce of the Future
- Deep Learning for Autonomous Vehicles
- The K-D Tree as an Acceleration Structure in Dynamic, Three-Dimensional Ionospheric Modeling
- Optimization Engine to Enable Edge Deployment of Deep Learning Models
News
- Association News
- Chapter News
- Corporate Member News
The K-D Tree as an Acceleration Structure in Dynamic, Three-Dimensional Ionospheric Modeling
Michael Opheim
HPC Internship Program, DoD High Performance Modernization Program, Alexandria, VA 22079,
Bethel University, St. Paul, MN 55112
John Haiducek
Remote Sensing Division, U.S. Naval Research Laboratory,
Washington, DC 20375
Abstract
It is understood that the Earth’s ionosphere contains charged particles that can degrade signals traveling to and from GPS satellites also inhabiting this layer of the Earth’s atmosphere. However, the concentration of these charged particles fluctuates extensively over time as a consequence of space weather patterns, making it difficult to accurately model the extent to which they are influencing radio signals. As such, this paper aims to provide an effective means to better trace radio signals as they encounter particles in the ionosphere. Using ionosphere particle concentration data provided by SAMI3, we found that it is possible to create an acceleration structure that allows one to measure how said particle concentrations degrade radio signal travel. This acceleration structure in particular was written in Fortran and utilizes K-D trees, which build in log-linear time complexity and perform nearest neighbor searches in logarithmic time complexity, resulting in fast execution times for problems of a sufficiently large size. Therefore, in conjunction with LightDA, a data assimilation library, it can be used to quickly build electron concentration trees that can be searched to facilitate rapid determinations regarding radio signal degeneration. In addition, the time involved with the tree build processes can likewise be improved through methods of parallelization. The research allows us to improve our models of the ionosphere through the dynamics it introduces to them, which has numerous implications for our current radio technologies.
Keywords: Ionospheric modeling, K-D trees, log-linear complexity
Introduction
The ionosphere is the outermost layer of the Earth’s atmosphere and contains anywhere from 103 to 106 charged particles per cubic centimeter across the entirety of its surface1. Additionally, it is also where many of our satellites currently reside. As such, this means that these satellites can be influenced by the ever-changing conditions of the ionosphere. The conditions are often altered by space weather phenomena and can have the effect of changing particle density within the atmospheric layer – which in turn can interrupt the operations of ionospheric satellites.
Most commonly, this becomes a problem because several satellites in the ionosphere are typically responsible for our radio communication and GPS technologies. When radio signals travel to and from these satellites and encounter electrons or other charged particles, they will be temporally delayed2. These delays can ultimately cause radio signal degradation and disruption, which can dramatically increase the time that it takes for them to reach their destinations.
While models of the ionosphere already exist to measure ionospheric particle concentrations and radio signal traversal and degradation, this project intends to improve upon one such model to better predict when and how radio signals will be influenced by the particle conditions of the ionosphere. Utilizing benchmarking tests and data provided by SAMI3, our work consisted of creating an acceleration structure that would allow us to logarithmically trace radio signals through toroidal ionospheric models. In other words, we hoped to create an algorithm that would do this while mitigating performance downtrends that may otherwise result from increasing complexity and data in our ionospheric representations. This was in order to (1) better permit the signal tracing process itself within these models, since they do not have traditional geometric axes which can easily facilitate such actions, and (2) make our models more accurate and apt to amendments with respect to the dynamics of the ionosphere and its particle densities.
Materials and Methods
Tree Structures
To ensure that our tracing algorithms performed at logarithmic time complexity, we decided to use a tree data structure. However, many types of tree structures exist which can execute such algorithms with this rapidity. Initially, we narrowed down all relevant options to the following: K-D trees, octrees, quadtrees, balanced box decomposition (BBD) trees. Due to the fact that quadtrees are specialized for two-dimensional data, and BBD trees do not store convex spatial regions, we did not consider them to be suitable for the intended application3. At this point, we determined that both octrees and K-D trees were quite similar in their performance, having loglinear time complexity to build and logarithmic time complexity to search. Although, since K-D trees had been established as a more useful data structure for previous research involving tracing through toroidal grids such as how our model is constructed4, we ultimately decided to utilize it for the purposes of our work.
Acceleration Structure
The acceleration structure itself was built in Fortran and compiled using GNU Fortran version 9.4.0. It creates K-D trees recursively, splitting an array of coordinates by cycling through dimensions at each tree level. In order to make the splitting process more effective, coordinates are sorted during each recursive call. Sorting is conducted using the standard C++ sorting algorithm included in C++17. Overall, the acceleration structure was written with object-oriented practices in mind and as a library that can be imported into any software conducting ionospheric modeling.
Testing
Several tests were created for the acceleration structure. In order to determine whether it could indeed perform at logarithmic time complexity, two distinct tests in particular were created which used integer and 32-bit real number coordinate arrays, respectively, and measured the execution runtimes involved with using the acceleration structure to find the nearest neighbor coordinate in each of them to an arbitrary, provided coordinate. The coordinates in these arrays were three-dimensional in nature and ranged from 0 – 100. Tests were performed with differing numbers of these coordinates, with each test gradually having its number of coordinates increased by a factor of ten (from ten up to one million). Each of these tests were run with ten trials per test. Ultimately, the resulting runtimes of these tests were averaged to determine whether or not the acceleration structure performed at a logarithmic time complexity.
After this, we performed another test using ionospheric particle concentration data provided by SAMI3. SAMI3 is a global, global, three-dimensional model of the ionosphere produced by the Center for Geospace Storms5. To administer this test, subsets of 32-bit real number coordinate points from SAMI3 were likewise read into the acceleration structure to create a tree of coordinate values and a nearest neighbor search query was conducted on an arbitrary coordinate that was provided to the resulting structure. Similarly to the integer and 32-bit real number tests above, tests using SAMI3 data involved performing ten trials per test, where each test was distinguished by the amount of SAMI3 data that it employed. In this case as well, each test had its number of coordinates increased by a factor of ten (from ten up to one million). Ultimately, the execution times of the trials of this test were also recorded for later analysis.
Results
Integer Test
Upon benchmarking the K-D tree acceleration structure using integers, it appeared that, for each factor of ten that was applied to the number of coordinates to be included in a given tree, the execution time to find a nearest neighbor for any arbitrary coordinate provided to the acceleration structure also increased by approximately a factor of ten. Visually this can be seen in Figures 1 and 2.
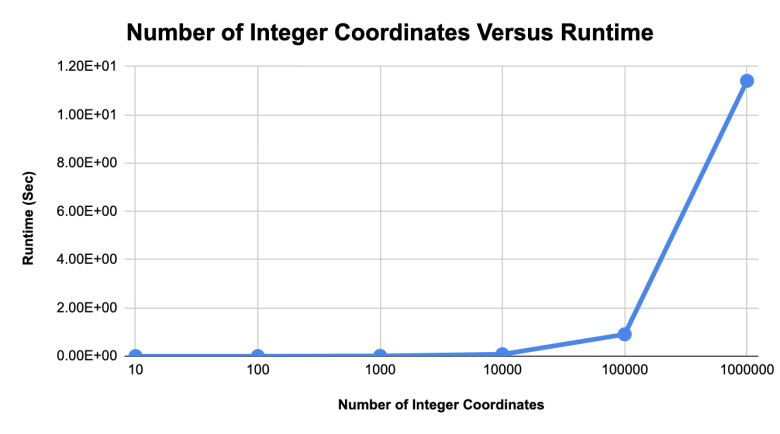
Figure 1: The runtime of the nearest neighbor searches for K-D trees containing different numbers of integer coordinates.
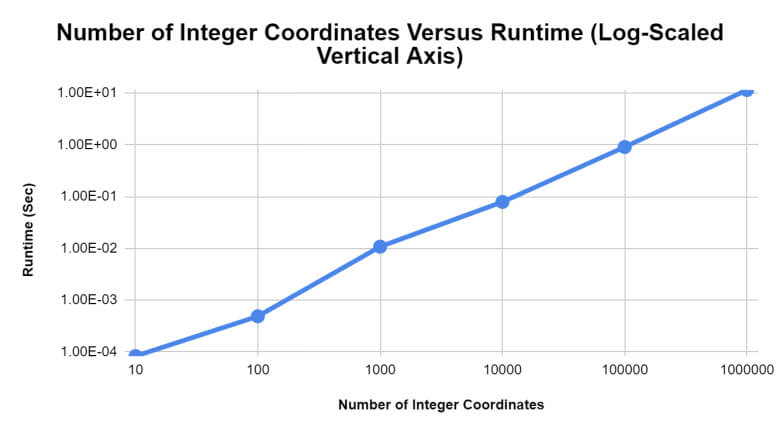
Figure 2: The log-scaled runtime of the nearest neighbor searches for K-D trees containing different numbers of integer coordinates.
In application, the K-D tree was not perfectly logarithmic in its execution times for nearest neighbor searches. Sources of error that might have led to this being the case may have been induced by phenomena such as hidden overheads and the inaccuracies involved with temporal runtime measurement.
32-Bit Real Number Test
When benchmarking the K-D tree acceleration structure using 32-bit real numbers, the results appeared quite similar to those achieved from the previous integer test. Once again, it seemed that, with each factor of ten that was applied to the number of coordinates to be included in a given tree, the time required to perform a nearest neighbor search for any arbitrary coordinate provided to the tree likewise increased by approximately a factor of ten, as shown in Figures 3 and 4.
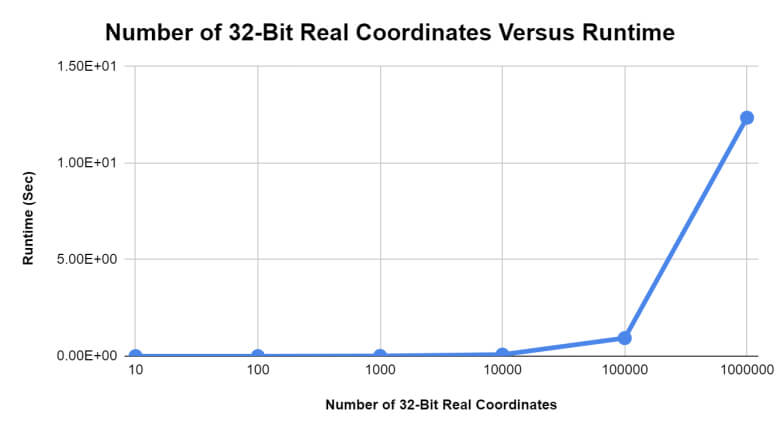
Figure 3: The runtime of the nearest neighbor searches for K-D trees containing different numbers of 32-bit real number coordinates.
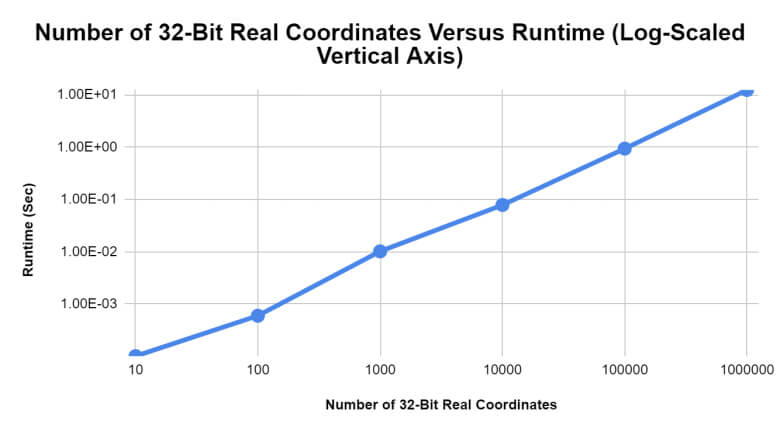
Figure 4: The log-scaled runtime of the nearest neighbor searches for K-D trees containing different numbers of 32-bit real number coordinates.
Though this test may have been impacted by the same possible sources of error noted in the previous test, the average runtime for this test was greater than that of the integer test overall. The average runtime for the trials in the integer test equated to approximately 2.07 seconds, whereas the average runtime for the trials in the 32-bit real number test equated to approximately 2.23 seconds (a difference of 0.16 seconds). This distinction in runtime was likely due to the precision involved with the 32-bit real number test. However, it further highlights the necessity of computational optimization with regard to dynamic ionospheric modeling.
SAMI3 Test
With one million SAMI3 three-dimensional coordinates, runtimes for using the acceleration structure on such data were comparable to those found in the previous two tests, with SAMI3 data producing approximately logarithmic execution times, see Figures 5 and 6.
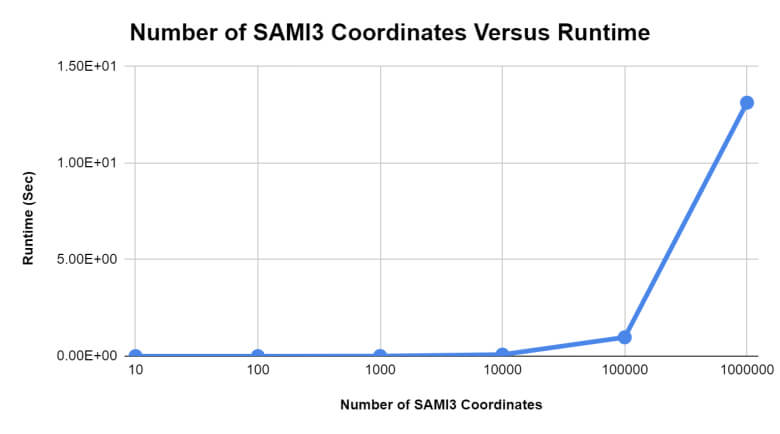
Figure 5: The runtime of the nearest neighbor searches for K-D trees containing different numbers of SAMI3 data coordinates.
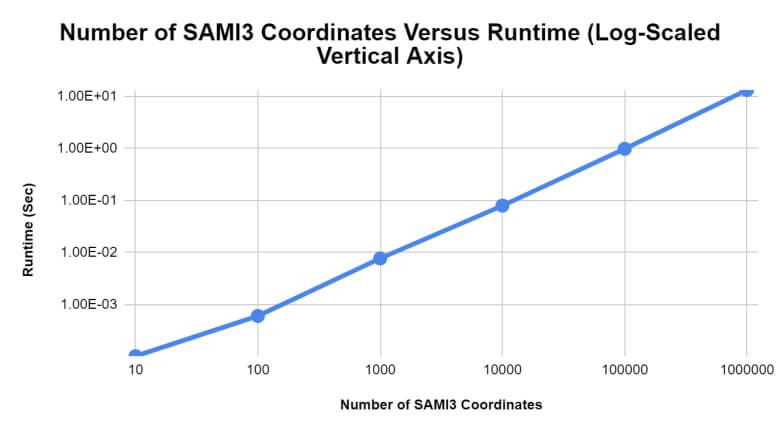
Figure 6: The log-scaled runtime of the nearest neighbor searches for K-D trees containing different numbers of SAMI3 data coordinates.
However, the average runtime for the SAMI3 coordinate test seemed to be approximately 2.37 seconds – a difference of 0.14 seconds from the 32-bit real number test, though they both employed the same type of data. This may be attributable to the fact that, while this test was vulnerable to the same potential sources of error that were listed in the integer test section of this paper, the SAMI3 data used in this test also had to be read from an external file.
Conclusion
Preliminary results of the K-D tree acceleration structure demonstrate that it can perform nearest neighbor search queries at an approximately logarithmic time complexity, a significant improvement over alternative, computationally intensive strategies for executing such requests. Experimentally, it was found that differing data types can also affect the performance of these queries, with our integer coordinate tests being quicker to execute on average than our 32-bit real number tests, including our SAMI3 data tests. Nonetheless, it is likely the case that the runtimes for these queries can be improved further with effective optimization procedures, such as parallelization. However, additional research is required to determine this.
Overall, we determined that the K-D tree allows one to expeditiously measure how ionospheric particle concentrations degrade radio signal travel, which is useful for making dynamic predictions with respect to the ionosphere’s influences on GPS signal propagation. Future avenues of research with regard to the K-D tree acceleration structure and ionospheric modeling may include using the K-D tree in relevant applications. For example, one such application that can prove useful is interpolation, where one could use the K-D tree to find the nearest neighbor coordinate points to arbitrary, provided points and subsequently interpolate between them. Another application is ray tracing, where the K-D tree could be used to determine where a ray, such as GPS signals or those produced by the sun, first intersect the SAMI3 grid. Thus, with this in mind, this research demonstrates that the K-D tree serves as an excellent acceleration structure with great potential for utility with respect to space weather modeling.
Impact of Summer Research Experience
Prior to this internship, I had experience facilitating research endeavors in the Chemistry Department, Neuroscience Department, and Psychology Department at Bethel University. Much of this work involved programming and contributing to software to improve the experimental efforts of those departments due to my background in computer science, as well as my background in various other scientific fields. Specifically, I have previously been responsible for developing motion-tracking programs, optimizing quantum chemistry software, and, outside of a computer science focus, writing the 2021 published historical study, “Vindication for Tin Foil Hats: An Analysis of Unethical Cold War Experiments and Their Enduring Consequences”. Beyond my experience with research, I have also held professional software engineering and data science positions and have worked with high-performance computing libraries and frameworks in my academic courses.
Through working on this project, I have accumulated a greater understanding of how to design and develop software. Much of this understanding has immediately helped me to better recognize and correct coding errors, as well as plan out how to make any program as efficient and optimized as possible. Additionally, by participating in the HIP internship, I have learned a considerable amount about a number of different software languages and established software programs. In particular, I have become more experienced with Fortran, but I have also extensively familiarized myself with C++, CMake, and scientific computing practices as a whole. Finally, this work has also abetted me in becoming more knowledgeable of how to conduct independent research within the field of computer science. In doing literature reviews, creating experimental designs and methodologies, analyzing and interpreting resulting data from experiments, and speaking publicly about my work on numerous occasions during my internship, I have gained a great deal of exposure to the standards and concrete applications of scholarly research, making me a more scientifically astute student.
As such, this program has served to improve my capabilities as a software engineer, a computer scientist, and an academic researcher. In light of this and the connections I have made through my time during it, this experience will be very influential in my future and has definitively prepared me for my later career and graduate studies. Moving forward, I now have an extensive practical understanding of how to apply computer science and mathematical theory to my code and to utilize such knowledge towards my personal goals. Thus, my internship has provided me with a valuable perspective into the applications of high-performance computing and, most notably, has significantly sharpened my background and aptitude in programming and engineering overall.
Acknowledgements
This work was supported in part by high-performance computer time and resources from the Department of Defense (DOD) High Performance Computing Modernization Program in collaboration with an appointment to the DOD Research Participation Program administered by the Oak Ridge Institute for Science and Education (ORISE) through an interagency
agreement between the U.S. Department of Energy (DOE) and the DOD. ORISE is managed by ORAU under DOE contract number DE-SC0014664. All opinions expressed in this paper are the author’s and do not necessarily reflect the policies and views of DOD, DOE, or ORAU/ORISE. Sponsorship of this work was provided by Department of Defense High Performance Computing Modernization Program (HPCMP) resources and the High Performance Computing Internship Program (HIP). The first author would like to thank Dr. John Haiducek for his mentorship and guidance in this work and the U.S. Naval Research Laboratory for its tangible support.
References
1.Robert Schunk and Andrew Nagy. 2009. Ionospheres: Physics, Plasma Physics, and Chemistry (2nd. ed.). Cambridge: Cambridge University Press.
2. Paul M. Kintner and Brent M. Ledvina. 2005. The Ionosphere, Radio Navigation, and Global Navigation Satellite Systems. Advances in Space Research 35, 5 (2005), 788–811. DOI:http://dx.doi.org/10.1016/j.asr.2004.12.076
3.David Eppstein, Michael T. Goodrich, and Jonathan Z. Sun. 2005. The Skip Quadtree: A Simple Dynamic Data Structure for Multidimensional Data. Proceedings of the Twenty-First Annual Symposium on Computational Geometry (July 2005), 296–305. DOI:http://dx.doi.org/10.1145/1064092.1064138
4.W. Saftly, M. Baes, and P. Camps. 2014. Hierarchical Octree and K-D Tree Grids for 3D Radiative Transfer Simulations. Astronomy & Astrophysics 561 (January 2014), A77. DOI:http://dx.doi.org/10.1051/0004-6361/201322593
5.J.D. Huba, G. Joyce, and J. Krall. 2008. Three-Dimensional Equatorial Spread F Modeling. Geophysical Research Letters 35, 10 (May 2008). DOI:http://dx.doi.org/10.1029/2008gl033509
Author Biographies
Michael Opheim is a recent graduate from Bethel University, having earned a B.S. in Computer Science, along with a B.S. in Mathematics and Data Science, a B.S. in Neuroscience, a B.A. in Mathematics, a B.A. in History, and a minor in Chemistry. Upon graduating, he has since been working as a software engineer with focuses in high-performance computing, artificial intelligence, and cybersecurity. He is personally interested in using his knowledge to contribute to the computational efforts of the future, including those involving the challenges that our current security, networking, and privacy standards endure in the face of evolving and ever-pervasive technologies. Moreover, he is also a preservationist and works to facilitate and support research that aims to conserve historical hardware and software for generations to come.
John Haiducek, Ph.D. is a research scientist at the U.S. Naval Research Laboratory where his research focuses on space weather modeling, particularly applied to the magnetosphere and ionosphere. He previously worked at the Air Force Research Laboratory where he engaged in computational fluid dynamics research applied to the development of high-power gas lasers. His research interests include space plasma physics, high-performance computing, scientific visualization, and data assimilation. He received his bachelor’s degree in physics from the U.S.
