

DECEMBER 2023 I Volume 44, Issue 4
Accelerating Image Recognition Using High Performance Computing
DECEMBER 2023
Volume 44 I Issue 4
IN THIS JOURNAL:
- Issue at a Glance
- NEW Editor Welcome
- Chairman’s Message
Conversations with Experts
- Memories from a Career in Army T&E: A Conversation with Dr. James J. Streilein
Workforce of the Future
- Workforce Development in Test and Evaluation
Technical Articles
- Tailoring the Digital Twin for Autonomous Systems Development and Testing
- Accelerating Image Recognition Using High Performance Computing
- Developing Model-Based Flight Test Scenarios
News
- Association News
- Chapter News
- Corporate Member News
Accelerating Image Recognition Using High Performance Computing
Abstract
We demonstrate the utility of a high-performance computing (HPC) environment for shaping evolving software products into new Department of Defense capabilities. We ported the initial software distribution of the Janus image recognition code (developed at the University of Maryland and further improved at MUKH Technologies, LLC under an exclusive license) to Intel x86 and IBM Power9 HPC architectures and performed baseline calculations. We profiled the code to identify computational bottlenecks and implemented partial fully connected layers of the deep convolutional neural network to allow scaling across multiple nodes. We obtained a decrease in training time from around 3 weeks to less than 2 days for a set of 300,000 identities and two million images. Finally, the HPC version of Janus was trained on datasets of 2.3 million identities and seventeen million images. We trained forty-five different models using subsets of the data with different filters and statistical sampling of demographics. We demonstrated that training against a much larger dataset produced better models with superior generalization properties, with caveats for the context and use cases of the trained models. The machine learning models have wide potential in face recognition, security, visual surveillance, and biometrics.
Keywords: Machine learning, high-performance computing, image recognition, face recognition, parallel computing, deep convolutional neural networks
Introduction
Historically, automated face recognition software works best on well-lit frontal poses, such as passport and driver’s license photos. It is less accurate when lighting is poor, resolution is low, faces are obstructed, camera angles vary, and facial expression is uncontrolled. In 2014, the Intelligence Advanced Research Projects Activity (IARPA) launched the Janus program (https://www.iarpa.gov/
During the Janus program, a University of Maryland-led team designed an end-to-end system for unconstrained face verification and recognition. They developed modules for face detection, pose estimation, fiducial extraction, gender determination hashing, and subject-specific clustering and integrated them into the end-to-end system, Chellappa (2018). IARPA supported five additional tasks as part of a transition research effort that ended in July 2020, Chellappa (2020). The results of the IARPA Janus efforts form the input to the current Army Combat Capabilities Development Command (DEVCOM) Army Research Laboratory (ARL) Janus transition effort. More details on University of Maryland (UMD) algorithms developed for the Janus program are found in Chen, et al., (2018), Ranjan, et al., (2018, 2019) and Zheng et al., (2019).
Background
The DEVCOM ARL operates one of 5 Department of Defense (DoD) Supercomputing Resource Centers (DSRCs) as part of the High Performance Computing Modernization Program – HPCMP (https://hpc.mil/). The computing platforms range from large-scale systems configured for compute-intensive applications, to GPU-dense computers tailored for AI/ML applications, to development platforms for assessing new and emerging technology. One role of the DSRC is supporting customers in maturing and transitioning technology into operational capabilities.
IARPA launched Janus to address perceived inadequacies in face recognition algorithms and it has successfully improved the performance of face recognition tools by fusing temporal and contextual information from social media. Our primary objective was to answer three questions: (1) How much speed up do we realize in training the models on high performance computers? (2) Does a high-performance computer allow us to train using a larger set of identities and images, and (3) Does using the larger dataset improve model accuracy?
We utilized three ARL HPC platforms: the IBM Power9 named SCOUT (SuperComputing OUTpost), a smaller version called Sofia, and the large x86-based Centennial. SCOUT and Sofia are GPU-dense with NVIDIA V100 training nodes and T4 inference nodes. Of the three systems, Centennial and SCOUT are shared systems within the HPCMP; Sofia was dedicated to the Janus project. SCOUT was the first ARL system designed specifically for machine learning workloads, ARL (2020) and Brewer et al. (2021). The center wide file system (CWFS) provided 3.3 petabytes (PB) of bulk storage accessible from all DEVCOM ARL HPC systems. Table 1 contains system details.
Table 1 DEVCOM ARL HPC System Capabilities
| System | type | nodes | cores | gpus | memory | storage |
| Centennial | SGI ICE XA | 1,848 | 73,920 | 56 Nvidia K40 Tesla | 253 TB | 12 PB RAID |
| Scout | IBM Power9 | 152 (with 22 training, 128 inference) | 6,080 | 132 Nvidia V100s; 512 Nvidia T4s | 45 TB | 330 TB SSD |
| Sofia | IBM Power9 | 17 (with 11 training, 2 inference) | 520 | 66 Nvidia V100s; 4 Nvidia T4s | 1 PB | 1.2 PB |
Technical Approach
Our approach followed six steps:
- Install the original MUKH Technologies, LLC University of Maryland Janus software to perform baseline testing and establish initial workflows
- Upload and process the DoD datasets
- Evaluate demographic statistics within the datasets and develop methods to address statistical skews in demographic representation for model training
- Update Janus software to improve function and performance
- Package the software using a Singularity container for simplifying deployment on other HPC systems
- Retrain Janus models using a larger DoD dataset
Software Implementation
The UMD-MUKH Janus software received from IARPA consisted of multiple components that perform data management, pre-processing, training, and inferencing, developed by different academic and private sector organizations. The software has two functions: training and inference. Training consists of three modules: face detection, thumbnail generation, and training. Inference consists of implementations to support the Noblis harness, a set of command line tools created by Noblis to allow execution of the JanICE API (application programmer interface), Anonymous (2020).
The specific version of the software developed by the University of Maryland, designated ‘3C’, is the version delivered to IARPA in the spring of 2020. A significant task was to work through the builds for the target HPC platforms to assemble, port, and package the software. Porting the software to the DSRC platforms required resolving deprecated dependencies with differing APIs and addressing the targeted HPC architectures. We validated the algorithms with the Noblis harness (inference tools) and used a subset of the full DoD dataset to test the inference tools and algorithms using a test dataset of 300,000 identities and 2 million images. Figure 1 depicts the Janus architecture as developed at the University of Maryland.
Data Preprocessing
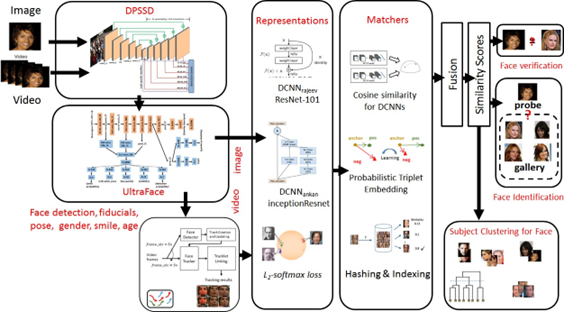
Figure 1 University of Maryland – Janus architecture
DEVCOM ARL used a subset of the full DoD dataset for testing the Janus algorithms, as noted above. The full DoD dataset consisted of image data that included at least one face, nominally containing 13.5 million Electronic Biometric Transmission Specification (EBTS) files with 7.8 million identities and 24.3 million images. We uploaded the 43 TB of data to the center wide file system. The authoritative data provides known subject verification, multiple poses of the same subject, and subject demographic details.
We anonymized the data with a bash script using a Java library to perform (a) anonymizing transaction and identity information, (b) ensuring that transaction and subject information correlated to provided information, (c) extraction of demographic information, and (d) extraction of facial images. We divided the files into 271 folders of 50,000 EBTS files each. A bash script assigned anonymized values as the files were processed, naming the extracted artifacts with the anonymized values. Demographics were extracted using a Java library which pulled data from EBTS type 2 fields and combined in a comma separated value file. Images were extracted from type 10 fields.
Three latent problems were discovered during testing of the Janus software: (1) dealing with special characters in Linux filenames caused some unexpected results, (2) renaming of image files with anonymizing values caused problems with duplicate image file names, and (3) some data labels needed to be corrected.
Balancing Demographics
In considering demographic data, some data is of low importance, for example, weight and height, whereas ethnicity, gender, and age are top demographics. After discussions with scientists at the National Institute of Standards and Technology (NIST), we developed a preprocessor to parse the data into training sets based on more balanced demographics than in the full set of identities. NIST scientists have worked with face recognition algorithm benchmarking for many years. They assess customer codes using a dataset of 100M images and have spent a great deal of time examining the effects of demographics,.
Improvements to the Software
Since delivery of Janus 3C in 2020, the most significant code improvement is a refactor of the original 3C system, extracting the fundamental recognition components into a new independent library. The new library handles the recognition pipeline components (detection, attribute extraction, descriptor extraction), leaving media loading, clustering, and template matching to the calling library. Additionally, the library pipeline implements a queue-based pipelining mechanism to ensure optimal batch sizes are used at each stage, without requiring any redundant image data to be held in memory. Focus was given to removing redundant data present in the 3C system. Together these improvements significantly improved both speed and memory usage over the 3C system. The updated system is referred to as 3C-prime, which we obtained in May 2022. Taking the same approach as for 3C, we installed the CPU version on Centennial and the GPU version on SCOUT and Sofia.
Previous experience with Janus 3C demonstrated training runtimes on the order of three weeks using 300,000 identities. Training with 300,000 identities was a limitation of GPU memory size at the time. The training component of the updated 3C-prime version of the software was limited to a single node using multiple GPUs. To support a larger number of identities, a multi-node multi-GPU solution was required. We incorporated a technique called Partial-FC (partial fully connected layers of the deep neural network). The training software and workflow were modified to support Partial-FC, An et al. (2021) and An et al. (2022).
Containerizing the Software for Portability
The training and inference codes were containerized using Singularity, a virtualized environment like virtual machines but lighter weight, i.e., it contains the Linux user space but employs the Linux kernel of the host computer, whereas a virtual machine encapsulates the entire operating system. Containers can include all the programs, libraries, and data no matter what version of Linux runs on the host platform. The goal is to make the application more portable and less labor intensive to move to new computers and new host operating systems.
Retraining the Janus Models
The process for retraining Janus began with the computation of a comma separated value file containing detected faces in the images using the Ultraface facial detection algorithm. Ultraface is a multi-tasking network that accomplishes face detection, landmark extraction, pose/age estimation, and gender determination, Chellappa (2018). This process locates face(s) in the image and is performed for each image to be used in the training process. Next, using the Ultraface data, images were converted into smaller thumbnails that contain only the detected face and places them in a subfolder by identity. Training took the generated thumbnails and trained the facial detection algorithm to identify faces and identities in the thumbnails. In some cases, triplet embedding, Sankaranarayanan et al. (2016), was applied for dimensionality reduction to improve results, but it did not add value in the current application.
Results
We examined training performance across different configurations of GPUs on the same platform to understand the impact of parallelization across nodes using the Partial FC method, Table 2. Each of three training runs was performed using six GPUs in configurations with one, two, and three nodes. For comparison, the time to train on a system of 8 Titan GPUs was 3 weeks.
Table 2 Training Times for Various Node/GPU Combinations
| Number of Nodes | Number of GPUs | Time (hours) |
| 1 | 6 | 95 |
| 2 | 3 | 39 |
| 3 | 2 | 40 |
It is seen that using a single node produces the lowest performance. This result is counter-intuitive since scaling across nodes incurs added communication cost. It is explained by the details of the Partial FC method, where the method itself distributes the final fully connected layer across nodes not GPUs; therefore, the computations performed in each case are not mathematically identical. Specifically, as the training is distributed across more nodes, fewer negatives are considered during the training. Despite this, and it is inherent in the benefit of the Partial FC method, effective training of the model proceeds without the mathematically complete set of all negatives. The impact of this observation is important, since it highlights both the advantages and application of Partial FC to treat large datasets using HPC platforms with multiple nodes.
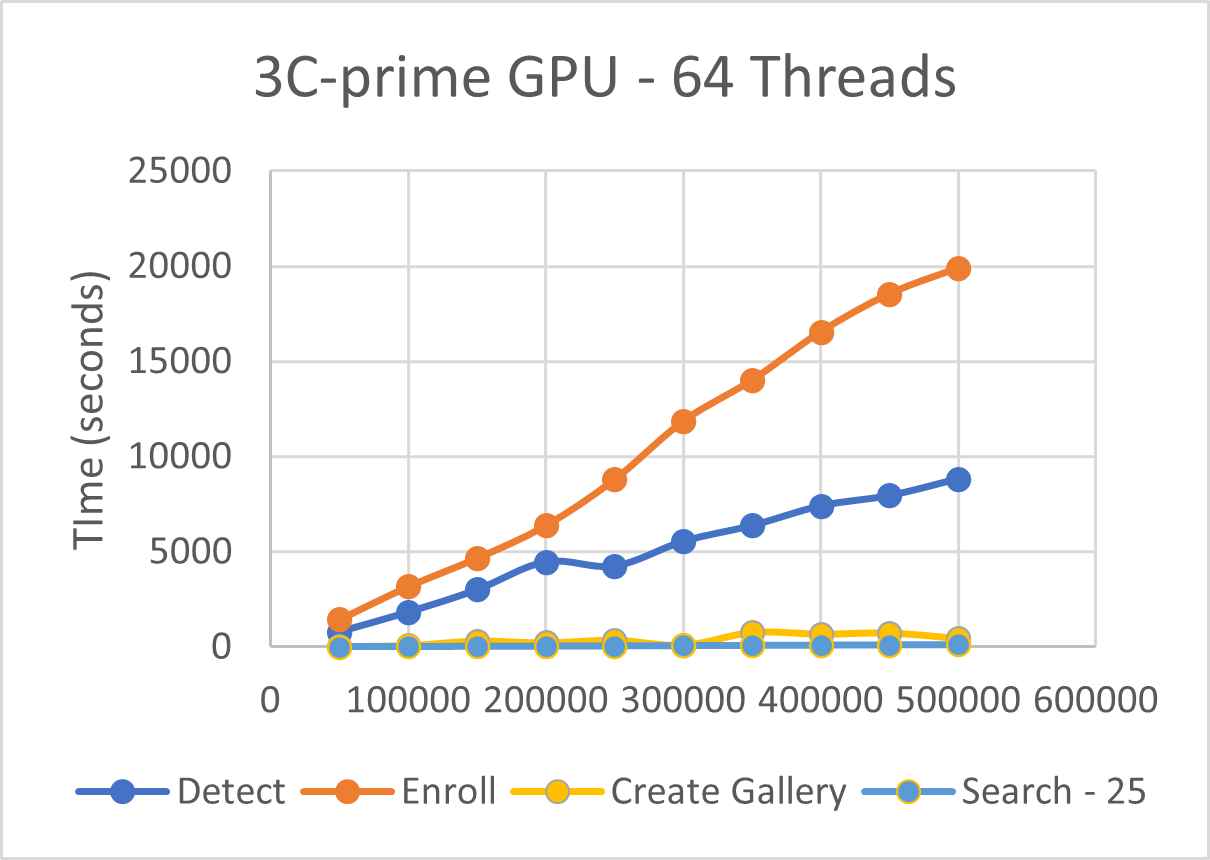
Figure 2 Performance Testing of Noblis harness
Figure 2 shows performance of 3C-prime utilizing GPUs for inference on a single SCOUT inference node. Datasets were tested in batches from 50,000 images to 500,000 images, increasing batch size by 50,000 per test. Performance scales linearly as the number of images increases. Detection and enrollment of those detections into template files take longer to process than gallery creation and search.
Robust face recognition requires access to large, unconstrained datasets. IARPA has taken several steps to make these available to developers and practitioners by creating IARPA Janus Benchmark A (IJB-A), Klare et al. (2015), IARPA Janus Benchmark-B (IJB-B), Whitelam (2017), and IARPA Janus Benchmark C (IJB-C), Maze (2018). The most recent effort, IJB-C, improves on the previous datasets by expanding the number of identities and images, and increasing the diversity of conditions under which the images were acquired, e.g., lighting, pose, perspective, etc. Figures 3 – 5 show performance of the top 10 performing training runs from 3C-prime Partial FC evaluated against IJB-C; 3C-prime evaluation against IJB-C is shown as well.
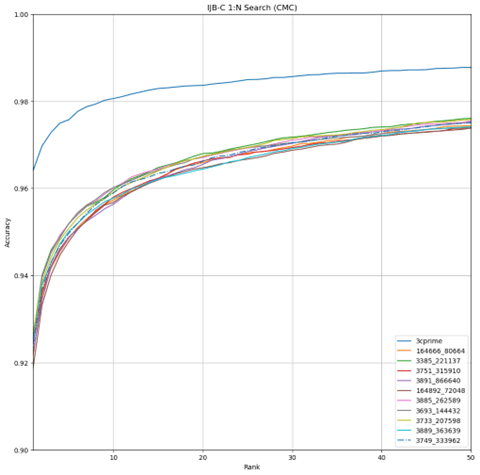
Figure 3 Accuracy of 3C-prime and Best Performing 10 Trained Models Against IJB-C
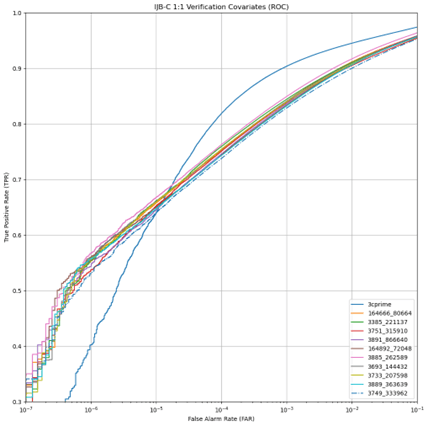
Figure 4 Covariate True Positive Rate of 3C-prime and Best Performing 10 Trained Models Against IJB-C
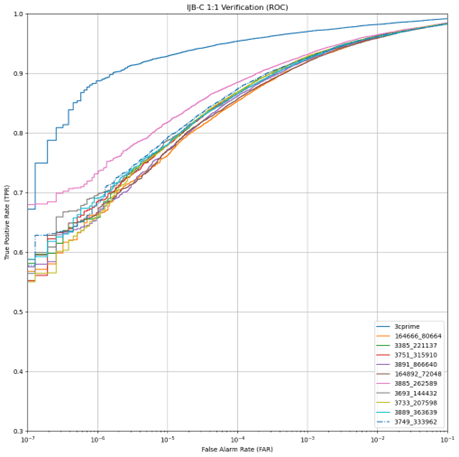
Figure 5 True Positive Rate of 3C-prime and Best Performing 10 Trained Models Against IJB-C
In the initial analysis of the quality of the models trained using the DoD dataset, verification was performed against CFP, LFW, and the larger IJB-C image datasets. Based on direct examination of selected images from the dataset, the facial images had a notable lack of expression and are described as typical of driver’s license photos. Even with non-frontal poses, the images contain relatively clear, staged photos with limited variability in expression, and with reasonably controlled lighting and image quality. This conclusion is not based on an exhaustive analysis, but sufficient examination was performed to convince us that the characterization is generally correct.
By contrast, the IJB-C image dataset contains facial images with greater variability in expression and more challenging poses. Further, the original 3C-prime was trained on a dataset containing some degree of such expressive variability. These observations led to the hypothesis that that newly trained models, in general, under-performed against 3C-prime because of the limited expressiveness in the DoD dataset. Additional potential contributing factors were also identified as the strongly skewed demographics, with the dataset comprising images that were mostly male and collected from a limited geographical region. While not clearly superior, the newly trained models have promising features.
One of the advantages of the DoD dataset is that it contains more identities than the original 3C-prime was trained against. To see how the number of identities in the training set affects performance, multiple dataset sizes were trained, specifically, dataset sizes of 300K, 1 million, 1.3 million, and 2.3. million identities were created. Figure 6 shows the 1-to-N search comparison of the top 2 performers from each size dataset along with the original 3C-prime. Figure 7 shows the same comparison for 1-to-1 verification covariates, and Figure 8 shows the comparison for 1-to-1 verification. As seen in these figures, performance improves when increasing from 300K to 1 million identities. Much less of a performance increase is realized with the increase from 1 million to 1.3 million or 2.3 million, indicating that increasing beyond 2.3 million identities may not be worth the additional compute time for the incremental increases in accuracy.
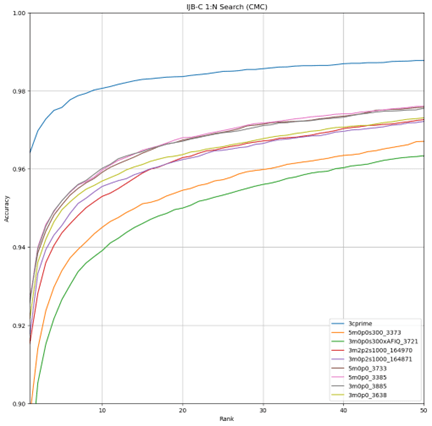
Figure 6 Accuracy of 3C-prime and Best Performing 2 Models Trained on DoD Data Against IJB-C
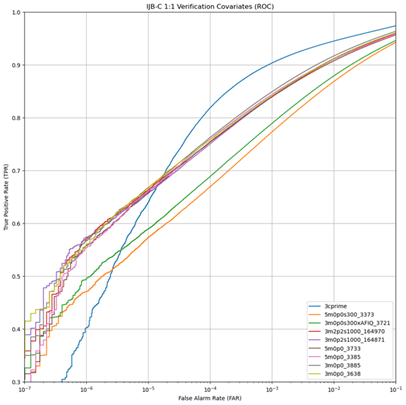
Figure 7 Covariate True Positive Rate of 3C-prime and Best Performing 2 Models Trained on DoD Data Against IJB-C
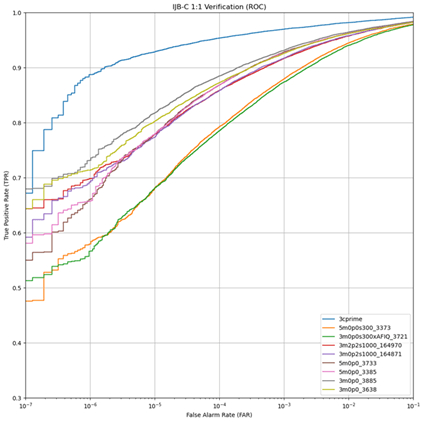
Figure 8 True Positive Rate of 3C-prime and Best Performing 2 Models Trained on DoD Data Against IJB-C
To evaluate the newly trained models within a context and use case involving less expressive and somewhat staged facial images, e.g., driver’s license photos, a verification experiment was constructed using the images held back from all training runs. This evaluation dataset contains a total of 200,000 identities from a total of 300,000 images. Half of the identities have two face images, while the other half has only one image. While this dataset contains significantly more identities than IJB-C, it has much less variability in demographics, pose, and facial expression, though we believe it may be more representative of specific use cases than IJB-C. The evaluation performed on this dataset provides insight into how the 3C-prime and new models perform in such cases.
The evaluation dataset was constructed to be disjoint from the training data to help avoid unrealistic performance. However, due to labeling errors in the DoD dataset, a few identities present in the evaluation dataset were also present in the training dataset (significantly less than 1% of the data). To ensure that the evaluation and training datasets were truly disjoint, we queried each of the identities having 3 or more examples (training identities) against the validation dataset. Visually, we determined that the top 10 matches were all repeated identities. However, outside of the top 2000 matches, we found no repeated identities. For peace of mind, we removed identities associated with the top 2500 matches, resulting in a final evaluation dataset containing a total of 197,581 identities with 98,802 two-image identities and 98,779 single-image identities.
We generated protocols for both 1:1 verification and 1:N search. The 1:1 verification protocol contained a total of 19,859,202 pairs consisting of all 98,802 positive pairs and randomly sampled 19,760,400 negative pairs (approximately 200 negatives for each positive). For the 1:N protocol, one of the images in the two-image identities was used to construct a gallery, with the other image used as a probe to search against the gallery. Additionally, the single-image identities are used as “distractors”, i.e., identities added to a gallery to increase the difficulty of the search. We evaluate the 1:N search protocol with and without distractors.
In the evaluation dataset, we found that the models trained on the DoD dataset significantly outperformed the 3C-prime models in both 1:1 verification and 1:N search. Both the 3C-prime and top-performing DoD-trained models perform very well on the dataset in an absolute sense, with 3C-prime correctly matching approximately 96% of probe images as the top match, and the top-performing DoD-trained models correctly matching more than 99% of probe images with the top match (Figure 9). We found that the 3C-prime system was slightly degraded with the inclusion of distractors (Figure 10), however, distractors had almost no impact on the top DoD-trained models (Figure 11).
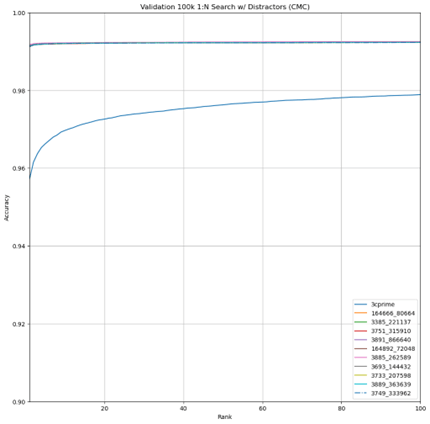
Figure 9 Accuracy of 3C-prime and DoD Data with ≤ 2 Images per Identity
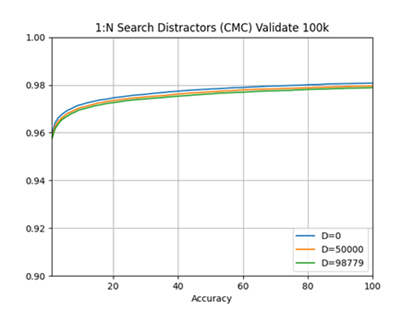
Figure 10 Accuracy of 3C-prime with Distractors
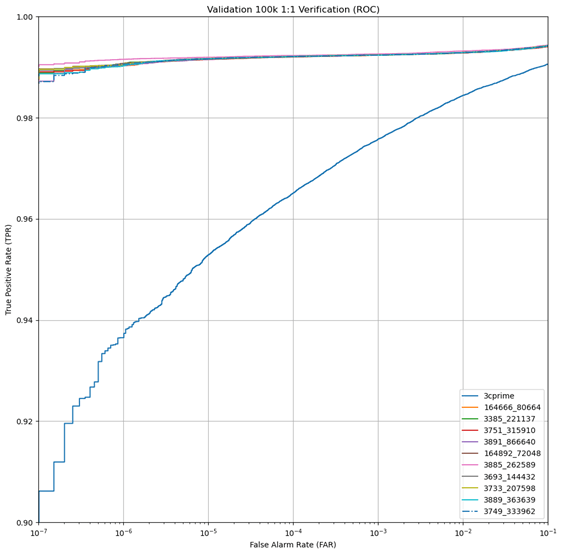
Figure 11 True Positive Rate of 3C-prime and Top DoD-Trained Models with Distractors
For 1:1 verification we find that 3C-prime produces 90% true positive rate (TPR) at 10-7 false acceptance rate (FAR) and top DoD-trained models produce an incredible 99% TPR at 10-7 FAR (Figure 12). True positive rate is a measure of how often a positive match is correctly identified. False negative rate is a measure of when a false match is correctly identified as false. From these results we see that the models trained on DoD data perform significantly better than 3C-prime on this evaluation data. This result indicates that, while DoD-trained models do not perform as well on “in-the-wild” media imagery of celebrities, like that of IJB-C, they perform significantly better on images collected in a way like DoD data.
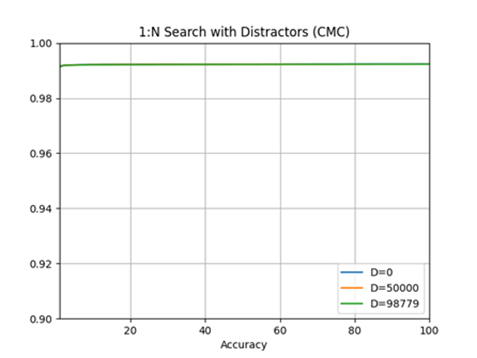
Figure 12 Accuracy of Top DoD-Trained Models with Distractors
Findings and Conclusions
Starting with the 3C-prime software release, a significant effort was required to port it to an IBM Power9 architecture. The Singularity-packaged container should now be portable to platforms of similar architecture, but this must be verified since there are dependencies on the configuration of the GPU hardware and drivers. The original 3C-prime was limited to a single node with multiple GPUs. We introduced the technique known as Partial FC to improve performance. Partial FC is a load-balanced, distributed classification training method that embodies a sparse variant of a model-parallel architecture for training face recognition. It can use multiple nodes each having multiple GPUs.
The initial 3C-prime release had a nominal limitation of 300,000 identities because of the limitations on GPU memory for a high-end GPU. Some data suggests this could be pushed to 600,000 identities with larger GPU memory resources, but it still represents a strict limit. The use of Partial FC allowed scaling over much larger datasets by distributing the final layer of the neutral network across multiple GPUs on multiple nodes. This removed the limitation in training dataset size, although some practical upper-bound limit undoubtedly exists.
Subsets of the DoD dataset were used to train models using different training dataset sizes, statistical sampling, and other hyper parameters. In general, results showed that the best performers were models trained with the largest datasets. When compared with the original 3C-prime model, the best performing new models were somewhat inferior, with the exception being that the receiver operating characteristic (ROC) curves of the newly trained models were much flatter and showed good performance at false alarm rates below 10-5, which represents a realistic operating point. (A ROC curve is an evaluation metric for binary classification problems.) When verified against a subset of DoD data that was held back and not used for training, performance of the best performing new models were significantly better than 3C-prime. The working hypothesis is that the DoD dataset contains facial images that lack significant expression and were taken in relatively favorable conditions. In this context, the models prove to be quite accurate, whereas when evaluated against a dataset with greater expression and demographic variability, the new models exhibit weaker results. We anticipate that if the models were trained on datasets having greater variability, the models would perform as well or better than the 3C-prime models.
Conclusions
The project successfully addressed the three major areas where questions existed. First, we demonstrated the ability to train on models much larger than previously reported. Whereas the original Janus/UMD work reported training on 300K identities, we were able to train on as many as 2.3 million identities, a limit imposed by the data available for training not by the software. Second, we demonstrated that training against a much larger dataset did, in fact, produce better models with some caveats for the context and use cases of the trained models. Finally, the work of the project could not have been easily carried out without the benefit of HPC resources for both pre-processing, dataset management, and training.
Acknowledgments
This research is based upon work supported in part by the Office of the Director of National Intelligence (ODNI), Intelligence Advanced Research Projects Activity (IARPA), via contract #2019-02260002 and interagency agreements between IARPA and the DEVCOM ARL. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of ODNI, IARPA, or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for governmental purposes notwithstanding any copyright annotation therein.
The authors appreciate the support and encouragement of Dr. Lars Ericson of IARPA during this effort.
Special thanks to Dr. Patrick Grother and Dr. Mei Lee Ngan of NIST for a valuable discussion of demographics and to Kevin Wright for keeping SCOUT and Sofia alive and well. Finally, we acknowledge and express appreciation to the HPCMP and the ARL DSRC for providing the HPC resources that made this project possible.
References
An, Xiang et al., “Partial FC: Training 10 Million Identities on a Single Machine,” 2021 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), 2021.
An, Xiang et al., “Killing Two Birds with One Stone: Efficient and Robust Training of Face Recognition CNNs by Partial FC,” arXiv:2203.15565v1, 28 Mar 2022.
Anonymous, “UMD Annotated Version of the Noblis Reference Manual of JANICE,” University of Maryland, March 2020.
ARL, IBM Power9 (SCOUT) User Guide, ARL DoD Supercomputing Resource Center, August 2020.
Brewer, W., Geyer, C., Kleiner, D. and Horne, C., “Streaming Detection and Classification Performance of a POWER9 Edge Supercomputer,” 2021 IEEE High Performance Extreme Computing Conference (HPEC), 2021, pp. 1-7, doi: 10.1109/HPEC49654.2021.9622852.
Chellappa, R. “Final Technical Report, Janus: Sparse Heterogeneous Representations and Domain Adaptive Matching for Unconstrained Face Recognition,” University of Maryland, July 2018.
Chellappa, R. “Final Technical Report, Janus Transition Contract,” University of Maryland, July 2020.
Chen, J.-C., Ranjan, R., Sankaranarayanan, S., Kumar, A., Chen, C.-H., Patel, V. M., Castillo, C. D. and Chellappa, R. “Unconstrained still/video-based face verification with deep convolutional neural networks.” International Journal of Computer Vision 126, no. 2-4, 272-291, 2018.
Grother, P. et al., “The 2017 IARPA Face Recognition Prize Challenge (FRPC),” NISTIR 8197, National Institute of Standards and Technology, https://www.nist.gov/programs-projects/face-recognition-prize-challenge, https://doi.org/10.6028/NIST.IR.8197, November 2017.
Klare, B. F., Klein, B., Taborsky, E., Blanton, A., Cheney, J., Allen, K., Grother, P., Mah, A., Burge, M., and A. K. Jain, “Pushing the frontiers of unconstrained face detection and recognition: IARPA Janus Benchmark A,” In IEEE CVPR, pp. 1931–1939, 2015.
Krizhevsky,A., Sutskever, I., and Hinton, G. E., “Imagenet classification with deep convolutional neural networks.” Advances in Neural Information Processing Systems (NeurIPS), pp. 1097-1105, 2012.
LeCun, Y., Bottou, L., Bengio, Y. and Haffner.P. “”Gradient-based learning applied to document recognition,” in Proceedings of the IEEE, vol. 86, no. 11, pp. 2278-2324, Nov. 1998, doi: 10.1109/5.726791.
Maze, B. et al., “IARPA Janus Benchmark – C: Face Dataset and Protocol,” 2018 International Conference on Biometrics (ICB), 2018, pp. 158-165, doi: 10.1109/ICB2018.2018.00033.
Ranjan, R., A. Bansal, H. Xu, S. Sankaranarayanan, J.C. Chen, C.D. Castillo, and R. Chellappa, “Crystal loss and quality pooling for unconstrained face verification and recognition”, arXiv preprint arXiv:1804.01159, 2018.
Ranjan, R., A. Bansal, J. Zheng, et al., “A fast and accurate system for face detection, identification, and verification”, IEEE Transactions on Biometrics, Behavior, and Identity Science, 1(2):82–96, 2019.
Sankaranarayanan, S., Azadeh, S., Castillo, C. and Chellappa, R., “Triplet probabilistic embedding for face verification and clustering,” Conference: 2016 IEEE 8th International Conference on Biometrics Theory, Applications and Systems (BTAS), September 2016, DOI:10.1109/BTAS.2016.7791205.
Whitelam, C., Taborsky, E., Blanton, A., Maze, B., Adams, J., Miller, T., Kalka, N., Jain, A. K., Duncan, J. A., Allen, K., Cheney, J., and P. Grother. “IARPA Janus Benchmark-B face dataset,” In IEEE CVPR Workshop on Biometrics, July 2017.
Zheng, J., Chen, J.C., Patel, V.M., Castillo, C. and Chellappa, R., “Hybrid Dictionary Learning and Matching for Video-based Face Verification”, Biometrics: Theory, Algorithms and Systems, Tampa, FL, Sept. 2019.
Author Biographies
JAKOB ADAMS is a software engineer with over 10 years of experience. Development experience includes machine learning model development, primarily in computer vision, end-to-end data pipelines, and model optimization. He also has experience in the development of automated testing systems and high performance computing.
RAMA CHELLAPPA, PH.D., is a Bloomberg Distinguished Professor in the Departments of Electrical and Computer Engineering and Biomedical Engineering at Johns Hopkins University, Baltimore, MD. Before moving to JHU, he was a Distinguished University Professor and a Minta Martin Professor at the University of Maryland, College Park. His current research interests span artificial intelligence, computer vision, image and video processing and understanding, machine learning and pattern recognition. He is a member of the National Academy of Engineering and has received numerous awards and recognition from many professional associations. He is a Fellow of AAAI, AAAS, ACM, AIMBE, IAPR, IEEE, NAI, and OSA.
J. MICHAEL BARTON, PH.D., Parsons Fellow, has worked on the Aberdeen Proving Ground since 2001 spending the first 10 years supporting the US Army Developmental Test Command and later the Army Test and Evaluation Command. He joined the Army Research Laboratory Computational and Information Sciences Directorate in April 2015, working in large-scale data analytics, high-performance computing, and outreach to test and evaluation and other ARL stakeholders. Dr. Barton’s entire career is in physics-based modeling and simulation. He spent 6 years as a consultant in the aerospace industry; 12 years as a contractor supporting the Air Force at the Arnold Engineering Developmental Center in Tennessee and the National Aeronautics and Space Administration Glenn Research Center in Ohio; and the first 4 years of his career with The Boeing Company in Seattle. He has worked for Parsons Corporation for the past 8 years. He received Bachelor of Science and Ph.D. degrees in engineering science and mechanics from the University of Tennessee-Knoxville and a Master of Engineering degree in Aeronautics and Astronautics from the University of Washington.
JAMES GABBERTY holds a B.S. degree in Aerospace Engineering from The University of Texas at Austin, and a M.S. degree in Computer Science from Pace University. He has worked in defense contracting for 4 years, 2 of those years being with Parsons. He’s experienced in government applications of computational electromagnetics, computational fluid mechanics, and most recently AI/ML.
JOSHUA GLEASON
SEAN HU, PH.D.
JAMIE JOHNSON
FRANK MOORE-CLINGENPEEL
ROBERT OSHIRO is a systems software engineer with over 35 years of experience in commercial and government systems. He has background in biometric, electronic warfare, aircraft avionics and computer systems. Experienced in hardware and software design including simulation, hardware-in-the-loop and recently Machine Learning integration of facial recognition software.
NEEHAR PERI received a B.S in computer engineering from the University of Maryland – College Park in 2021. He is currently pursuing a Ph.D. in Robotics at Carnegie Mellon University. His research interests include computer vision, machine learning, and robotics.
DAVID RICHIE, PH.D., is the Founder and President of Brown Deer Technology, directing all technical efforts of the company since 2003, including research, development and engineering of software and hardware technologies for high-performance and accelerated computing. Recent work includes the development of software supporting co-processor acceleration, the design of a hybrid RISC-V AI/Edge processor for low-power applications, and the design of a RISC-V digital signal processor (DSP). Dr. Richie possesses broad domain expertise ranging from computational physics to device simulation and C5ISR applications. He has a Ph.D. in Physics from the University of Illinois at Urbana-Champaign, a B.S.E.E. in Electrical Engineering from the University of Wisconsin-Madison, and over 26 years of experience in the high-performance computing (HPC) industry, including the development and optimization of computationally intensive software simulation packages, the development of HPC middleware for accelerated parallel programming, and the design of high-performance reconfigurable computer architectures.”
VIRGINIA TO, is the Director of Army Programs for the Energetics Technology Center in Indian Head, Maryland, where she identifies and develops strategic partners in science and technology, test and evaluation, and acquisition engineering to define and manage artificial intelligence/machine learning and data analytics projects. Virginia has more than 25 years’ experience as a project/program manager for the DoD and Army leading traditional and distributed teams of academia, industry, and government research and development personnel in addressing organizational constraints to best serve the interests of each program’s objectives. Virginia also serves as the outreach and workforce development coordinator for Army Research Laboratory’s computational science and robotics initiatives, introducing middle and high school students to computing and autonomy technologies and applications, as well as mentoring many high school and college students. She holds an M.S. in Computer Science from The Johns Hopkins University, and a B.A. in Mathematics from Barnard College.
