

MARCH 2024 I Volume 45, Issue 1
Towards Multi-Fidelity Test and Evaluation of Artificial Intelligence and Machine Learning-Based Systems
MARCH 2024
Volume 45 I Issue 1
IN THIS JOURNAL:
- Issue at a Glance
- Chairman’s Message
Book Reviews
- Book Review of Systems Engineering for the Digital Age: Practitioner Perspectives
Technical Articles
- Towards Multi-Fidelity Test and Evaluation of Artificial Intelligence and Machine Learning-Based Systems
- Developing AI Trust: From Theory to Testing and the Myths in Between
- Digital Twin: A Quick Overview
- Transforming the Testing and Evaluation of Autonomous Multi-Agent Systems: Introducing In-Situ Testing via Distributed Ledger Technology
- Decision Supporting Capability Evaluation throughout the Capability Development Lifecycle
Workforce of the Future
- Developing Robot Morphology to Survive an Aerial Drop
News
- Association News
- Chapter News
- Corporate Member News
![]()
Towards Multi-Fidelity Test and Evaluation of Artificial Intelligence and Machine Learning-Based Systems
Robert J. Seif
School of Mechanical Engineering, Purdue University
![]()
Atharva Sonanis
School of Mechanical Engineering, Purdue University
![]()
Laura Freeman
Virginia Tech National Security Institute
![]()
Kristen Alexander
Director, Operational Test and Evaluation, Office of the Secretary of Defense
![]()
Jitesh H. Panchal
School of Mechanical Engineering, Purdue University
![]()
Abstract
With the broad range of Machine Learning (ML) and Artificial Intelligence (AI)-enabled systems being deployed across industries, there is a need for systematic ways to test these systems. While there is a significant effort from ML and AI researchers to develop new methods for testing ML/AI models, many of these approaches are inadequate for DoD acquisition programs because of the unique challenges introduced by the organizational separation between the entities that develop AI-enabled systems and the government organizations that test them. To address these challenges, the emerging paradigm is to rigorously test these systems throughout the development process and after their deployment. Therefore, to implement testing across the acquisition life cycle, there is a need to use the data and models at various levels of fidelity to develop a cohesive body of evidence that can be used to support the design and execution of efficient test programs for systems acquisition. This paper provides a perspective on what is needed to implement efficient and effective testing for an AI-enabled system based on a literature review and walk-through of an illustrative computer vision example.
Keywords: Artificial Intelligence, Machine Learning, Testing and Evaluation.
1. Introduction
Artificial intelligence (AI) and machine learning (ML) are becoming increasingly important for a wide range of applications. Several researchers have noted that these systems fundamentally differ from traditional mechanical or digital systems [1]. Traditional systems can undergo Test and Evaluation (T&E) sequentially, progressing from unit testing to system integration testing to operational testing, without necessarily needing to revisit prior testing phases. However, this is no longer possible with systems enabled by AI/ML. AI-enabled systems can learn and change over time from development to fielding. This can result in the late discovery of issues in the AI model and its interactions with the operational environment, leading to high costs and late-stage churn.
Test and evaluation of ML-enabled systems differs from traditional systems in several ways. First, randomness plays a significant role in ML testing. The results of ML systems are often difficult to reproduce due to various sources of randomness, including random data, random observation order, random weight initialization, random batches fed to the network, and random optimizations in different versions of frameworks and libraries [2]. This randomness adds complexity to the testing process and necessitates robust testing strategies [3] that account for its influence. Second, collecting reliable testing datasets can be labor-intensive, and generating a comprehensive test oracle is often infeasible. This limitation introduces potential biases and can affect the performance and generalizability of ML systems. Third, ML testing encompasses multiple components that need to be tested. This includes the ML model and the data, the learning program, and the underlying framework. Each of these components can introduce latent errors that affect the overall performance of the ML system. Fourth, the behaviors of an ML model change as the training data are updated. This dynamic nature of ML systems necessitates testing and monitoring to detect any shifts in behavior and ensure that the model’s predictions remain accurate and reliable. Fifth, traditional test adequacy criteria for software, such as line coverage, branch coverage, and dataflow coverage, are inadequate to assure machine learning software’s unique characteristics. ML-enabled systems rely heavily on data and complex computations, making it necessary to develop novel test adequacy criteria that consider the specific challenges and requirements of ML testing. Chandrasekaran et al. provide a complete overview of the challenges and current best practices captured by academic research in [4].
Beyond these technical challenges in the T&E of AI/ML systems, additional challenges arise due to the nature of the acquisition processes. While companies developing AI techniques have access to training and testing data, the Department of Defense (DoD) may not have proprietary access. The DoD may have mission-specific sensitive data that may be useful for training ML models, but it may not be possible to share the data due to security concerns. In such scenarios, the DoD must rely on stage-gate processes that regulate and protect critical government information to ensure it is used safely and effectively.
Existing testing and evaluation methods followed by the DoD are based on discrete testing phases [5]. These methods impose additional challenges for the T&E of AI-enabled systems as Contractor Testing (CT), Developmental Testing (DT), and Operational Testing (OT) have different objectives, are conducted by different organizations, and reflect different levels of operational fidelity, i.e., the levels of accuracy with which a system and its environment is captured. The result is that test programs will need help integrating information on AI model performance across these testing phases. Technology is advancing faster than the methods to test and comprehend them, leading to a range of test methods for technologies that may serve the same purpose or operate in similar environments [6].
Recent efforts in the DoD have emphasized the need for integrating testing and shifting operational realism earlier, termed “Shift Left,” to break down these organizationally driven barriers to testing. This paper explores integrating evidence for testing and evaluation generated by different fidelities of models and scenarios. We also provide a perspective on a framework for integrating multiple fidelities of models for evaluating AI/ML-based systems. By incorporating multiple levels of fidelity, the framework ensures a thorough evaluation of system performance, addressing issues of robustness and adaptability. We illustrate the proposed approach using an example of “Adversary Target Detection.”
The paper is organized as follows. Section 2 reviews the literature on AI/ML testing and the DoD test and evaluation processes and highlights the challenges in T&E of AI/ML-based systems for DoD acquisition. Section 3 provides an overview of the emerging perspective on transforming T&E, which supports adequate testing of AI-enabled systems. Section 4 describes an illustrative example of adversary target detection, and Section 5 provides a framework for implementing T&E using multi-fidelity models.
2. Literature Review
2.1 Testing and Evaluation of AI/ML Systems
Testing ML has been explored by two distinct communities: the ML scientific community (MLC) and the software testing community (STC). These communities possess different approaches to AI/ML testing. In MLC, an ML model is tested to estimate its prediction accuracy and improve its predictive performance. Such testing occurs during the model development phase, utilizing validation and test datasets to evaluate the model’s suitability based on the training dataset [7]. On the other hand, STC considers software as a system, identifying use cases, weak points, and boundary conditions of the software. STC identifies how data is represented, held, transferred, and utilized, and attempts to identify weaknesses in the processes present.
2.1.1 Testing the Accuracy on Benchmark Datasets
One common approach to quantitatively measure the performance of AI/ML models is to compare the algorithm’s output with ground-truth data, typically generated by human operators (e.g., marking the boundaries of target objects for computer vision problems). Notably, specialized tools for generating ground-truth data in video sequences have been developed and documented in [8] and [9]. These tools facilitate the creation of benchmark datasets and enable the comparison of algorithm performance on a standardized and competitive basis. This approach contributes to the advancement of the field by providing a standardized framework for evaluating and benchmarking the performance of detection algorithms [10]. Benchmark datasets are standardized collections of data used extensively in the machine-learning community to objectively measure an algorithm’s performance. They typically consist of a training set, used for the model learning process, and a test set, used to evaluate the performance of the trained model. These datasets have been carefully curated, cleaned, and often come with labels allowing for supervised learning. Some of the most frequently used benchmark datasets include the MNIST database [11], commonly used for handwritten digit recognition tasks; the CIFAR-10 and CIFAR-100 datasets [12], which consist of color images spread across 10 and 100 classes, respectively; and the Iris dataset [13], a classic in the field of machine learning, known for its use in simple classification tasks.
Creating a dataset specifically tailored to meet the requirements of a particular application holds immense importance in the realm of ML. The datasets, ideally, should encapsulate the diversity and intricacies of real-world data that the model is expected to encounter. It involves collecting, cleaning, and formatting data in a way that can be easily used for training ML models [14]. Depending on the problem, this could range from gathering vast amounts of text for natural language processing tasks to obtaining labeled images for computer vision applications or collecting sensor data for predictive maintenance. Once a suitable dataset is created, the next critical step is establishing a benchmark. A benchmark serves as a reference point against which the performance of various ML models can be measured. It could be a previously established high score on a specific dataset or task, the performance of a conventional method, or a theoretically optimal solution. It is crucial to note that the benchmark should ideally be challenging yet achievable, pushing for continuous improvement without discouraging efforts.
The VEDAI dataset [15] is a prime example of the need for new datasets and benchmarking in machine learning. It was specifically designed to facilitate the development and benchmarking of small target detection algorithms, focusing on vehicle detection in aerial images. The VEDAI dataset was created with specific criteria in mind. The dataset includes diverse targets, target types, and backgrounds, enhancing its representativeness. Targets were deliberately chosen to be small in pixel size, reflecting real-world scenarios. Ground-truth annotations accompany the dataset, enabling the development and evaluation of target detection algorithms. The VEDAI dataset serves as a comprehensive benchmark for small target detection in aerial images, highlighting the importance of specialized datasets and benchmarking in machine learning [15].
The commonly used metrics for assessing performance on these datasets include accuracy, precision, and recall. Accuracy measures the proportion of total correct predictions. Precision evaluates the proportion of correct identifications, while recall measures the proportion of actual positives that were identified correctly. Each of these metrics provides unique insights into the strengths and weaknesses of the model, giving a comprehensive overview of its performance.
2.1.2 Testing and Evaluation (T&E) Frameworks
A T&E framework, which comprises a set of methods, tools, and procedures, serves the core purpose of assessing, scrutinizing, and affirming the performance and safety parameters of machine learning (ML) models. Several key aspects must be carefully considered when designing a T&E framework. These include the accessibility of data, the identification, and preparation for worst-case scenarios, all the parameters that likely govern the system’s behavior, and the variety of information, simulation models, and test data generated throughout the development process. The framework is tailored to meet the specific requirements of the system, with a focus on addressing key areas and objectives. The evaluation process becomes more targeted and effective by customizing the framework to target specific areas of concern, such as code-data interaction, missing test oracles, robustness metrics, and ethical machine reasoning. This approach allows for a systematic and thorough assessment of the system’s performance and safety, enhancing its suitability for real-world applications. Existing frameworks can be classified into application-specific, ML-technique-specific, and scenario-specific frameworks, as described below.
Application-specific frameworks: In application-specific frameworks, both the learning-based system as a whole and its sub-systems can be tested individually and as an integrated unit. For example, consider the Unmanned Aerial Vehicle Assessment and Testing (UAVAT) framework [16]. This framework is divided into hardware and software components, each crucial in the overall evaluation process. The hardware components are described, highlighting their interactions and dependencies. Similarly, the software components are outlined, introducing the concept of test modules that facilitate the testing of various software functionalities. This structured approach ensures comprehensive testing of hardware and software aspects [17], enabling a thorough assessment of the UAV system [16].
ML-technique-specific methods: For instance, DeepXplore [18] is a differential white-box testing technique designed for deep learning models. It extends the ideas of code coverage in software testing to neuron coverage by exploring different paths and behaviors of neural networks to identify potential vulnerabilities and improve their robustness. DeepTest [19] employs a greedy search approach with realistic image transformations, such as changing brightness, contrast, translation, scaling, and rotation, to generate diverse and challenging test cases that evaluate the model’s performance across various scenarios. These techniques contribute to a more comprehensive and effective evaluation of the ML system.
Scenario-specific frameworks: For example, adversarial attacks are a critical consideration within the T&E framework. These attacks involve modifying the original input data so that the model’s output is significantly impacted. Adversarial attacks aim to exploit vulnerabilities in ML models, highlighting potential weaknesses and shortcomings. The system’s robustness and resilience can be assessed by subjecting the ML system to various types of attacks, such as evasion attacks where the attacker modifies the input data to evade detection [20].
2.1.3 Regulations and Standards
In machine learning (ML), regulations and standards are crucial in ensuring the verification and safety of ML systems across various domains. However, developing well-established guidelines for ML system development and deployment is still an ongoing process. These guidelines are necessary to address the unique challenges ML systems pose and ensure their reliability and safety [21].
Several examples of standards and initiatives that are emerging in the ML domain include the European Aviation Safety Agency (EASA) AI Roadmap [22], ANSI/UL4600 Standard for Evaluation of Autonomous Products [23], SAE G-34 [24], SAE G-34/EUROCAE 114 Artificial Intelligence in Aviation working group, ISO 26262, known as “Road Vehicles – Functional Safety,” [25], and Artificial Intelligence Medical Devices (AIMD) [26]. These standards aim to provide guidelines and frameworks for the verification, safety, and reliability of ML systems in specific domains and industries.
While these standards and initiatives show promise in addressing the verification, safety, and reliability challenges in domain-specific ML systems, such as autonomous vehicles, their shortcomings lie in the need for domain-independent guidelines and methodologies for a wide range of AI/ML-based systems. Efforts to align these regulations and standards across domains and industries could enhance their effectiveness, promoting safety and reducing costs in deploying ML systems. Developing and adopting regulations and standards are essential steps in ensuring the responsible and ethical deployment of ML systems. By establishing guidelines and frameworks, these regulations and standards contribute to ML systems’ overall safety and trustworthiness, facilitating their integration into real-world applications [21].
2.2 DoD Test and Evaluation Processes
The DoD has comprehensive guides for testing and evaluation [27, 28]. Existing methods of Test and Evaluation (T&E), such as the Department of Defense (DoD) 5-step method [29], provide a framework for evaluating systems during the acquisition process. It comprises five distinct steps: planning, test and evaluation development, test and evaluation execution, data analysis and reporting, and decision-making [29]. The planning step involves the formulation of a Test and Evaluation Master Plan (TEMP) that delineates the overarching strategy for T&E activities, with a focus on identifying critical operational issues, measures of effectiveness, measures of suitability, measures of performance, and technical parameters necessitating evaluation [30]. Subsequently, during the test and evaluation development step, detailed test plans and procedures are formulated, and customized to suit the specific system under examination. Concurrently, the development of test instrumentation and data collection systems takes place, facilitating the collection and analysis of pertinent test data. Moving forward, the test and evaluation execution step entails the physical execution of tests and the acquisition of performance-related data. This step encompasses both physical testing and modeling and simulation approaches. The data analysis and reporting step involves comprehensively examining test data to assess the system’s performance vis-a`-vis predetermined parameters. The resultant findings are presented in detailed reports, including recommendations for further testing or system enhancements. Ultimately, the decision-making steps employ the insights derived from the T&E process to inform critical acquisition decisions. These decisions therefore consider various factors such as system performance, cost, schedule, and technical risks [30].
2.3 Challenges in T&E of AI for DoD Acquisition
While the aforementioned general T&E process provides a structured framework for testing and evaluation, it exhibits limitations when applied to the testing and evaluation of AI-based systems due to the dynamic nature of AI-based systems driven by machine learning algorithms. Moreover, traditional T&E methods primarily focus on verifying functionality based on predefined rules and logic, which is insufficient for evaluating AI-based systems. The testing process must encompass unexpected inputs and assess the system’s capability to handle diverse datasets. Additionally, the evaluation of AI-enabled systems extends beyond prediction accuracy or output quality, necessitating the examination of factors like robustness, interpretability, and transparency, which traditional T&E methods often do not adequately consider [29].
Furthermore, the limited availability of test data for AI-enabled systems, especially early in the development cycle, presents a significant limitation for T&E. Traditional methods heavily rely on executing live tests to collect data to evaluate system performance against predetermined measures. However, AI-enabled systems require a large set of test data to characterize model performance across an operating region, making accurate performance assessment challenging. Other challenges include an inadequate representation of real-world conditions, insufficient test scenarios, and stimuli, limited test sample size, and time & cost constraints. Challenges in assessing system interoperability, resilience, and limited consideration of cybersecurity are particularly critical in ML/AI systems because of their complexity and black-box nature.
Creating comprehensive and representative test scenarios encompassing the full spectrum of operational situations can prove challenging. As a result, certain critical scenarios or stimuli may be overlooked or not sufficiently represented, resulting in incomplete assessments of system capabilities. There is also a difficulty in accurately replicating real-world operational conditions during all phases of testing. The controlled environment in which much of contractor and developmental testing is conducted may fail to fully capture the intricacies and uncertainties found in actual operational scenarios. Consequently, a system’s performance in the test environment may not align with its real-world performance, leading to potential inaccuracies in assessing system effectiveness and suitability [29,31]. Moreover, unrealistic or simplified test stimuli may hinder the ability to fully capture a system’s response to complex operational challenges [29, 31].
Resource constraints and practical considerations may render it infeasible to conduct testing on many systems or iterations. Consequently, the limited sample size may introduce statistical uncertainties and pose challenges in generalizing the test results to the broader population of systems or operational conditions [7]. Planning, executing, and analyzing tests require substantial time and resources. However, limitations imposed on the T&E activities in terms of time and budget may impact the thoroughness and comprehensiveness of the testing process. Insufficient time for testing may lead to rushed evaluations or limited coverage of critical test objectives. Similarly, budget constraints may impede the allocation of resources necessary for comprehensive testing, resulting in potential gaps in data collection and analysis [29].
Assessing system interoperability within complex operational contexts proves challenging for the current T&E process. Many DoD systems need to operate within larger networked or joint operational environments. However, the T&E process often struggles to adequately evaluate how systems interact and exchange data with other platforms or networks. As a result, the current process may not provide a comprehensive assessment of system interoperability and its impact on overall mission effectiveness [29,30]. Additionally, the current T&E process may not fully account for new cybersecurity vulnerabilities and threats that AI-enabled systems introduce. With the increasing reliance on networked and software-intensive systems, cybersecurity has emerged as a critical concern. Assessing the resilience of systems against cyber-attacks and evaluating their ability to maintain operational effectiveness in the face of cybersecurity threats require specialized expertise and dedicated testing approaches that may not be sufficiently integrated
into the existing T&E process.
3. EMERGING PERSPECTIVE: TRANSFORMING T&E
To address these gaps and limitations, the T&E community has highlighted the need to transform T&E to capitalize on new technologies to generate “transformative changes to T&E infrastructure, tools, processes, and workforce.” The Director, Operational Test and Evaluation (DOT&E) published a strategy and implementation plan to ensure that T&E is adequate for rapidly accelerating technologies [32]. Notable goals of the strategy relevant to the T&E of ML-enabled systems include:
- Discoverable, accessible, and secure datarepositories
- Near real-time test data analysis andassessment
- Established tools and processes that optimize integratedT&E
- Standardized and increased use of credible digital tools/twins inT&E
- Adequate assessment of operational and ethical performance of AI-enabledsystems
- Continuously track and mitigate any degradation of operational performance of DOD systems in theater[32].
The achievement of these goals will aid in overcoming the challenges posed by the dynamic nature of AI. They support the ability to integrate information across multiple phases of testing with various levels of fidelity and the ability to assess system performance under varying conditions and complexities of the environment.
Freeman [1] highlights this perspective using the following themes:
- T&E must occur across the acquisition life cycle, until the system retires.
- Integrating information from disparate data sources requires methods.
- Data management is foundational.
- AI systems require a risk-based test approach.
- Operational relevance is essential.
Wach et al. [33] combine Isomorphism and Bayesian methods to create a framework to evaluate AI across different fidelities and contexts. These methods allow for a probabilistic approach to using a model as deterministic approaches do not apply to new AI. They suggest that models should be viewed as a source of learning for the AI and how it responds across the fidelities it operates in.
The general idea behind these approaches is that the entire set of models and tests should be viewed as the “body of evidence” with operation states across different surrogates of models, operating environments, and simulations, leading to a probability for success. Implementing such approaches requires us to determine what information each model provides about the operational performance of the eventual system. There is a need to characterize each model, how different models relate to each other, and to the performance of the overall system, and how these models can be used synergistically to validate the system’s performance (not only when it is delivered, but also as it evolves).
4. ILLUSTRATIVE EXAMPLE: ADVERSARY TARGET DETECTION
The Adversary Target Detection system aims to accurately detect and classify potential threats in a fielded zone. This system uses machine learning algorithms and data analysis techniques to identify and track adversary targets. The requirements include hardware, software, input, output, scalability, transferability, integration, robustness, and reliability. For the software system, specific requirements include object detection, object classification, object location, top-view grid mapping, and object tracking.
Consider the design of a system where a video feed is captured from a drone, which is then analyzed using machine vision techniques to identify, locate, classify, and track targets such as people and vehicles. The desired output consists of the coordinates and trajectories of the targets. The functional operation of the AI/ML software system, as depicted in Figure 1, consists of object detection, tracking, and mapping & visualization.
The object detection subsystem is responsible for processing the raw video input and employs a custom object detection model trained on YOLOv3 [34]. This subsystem identifies and detects objects within the video feed and produces location coordinates or bounding boxes along with their respective classes as the output. The object tracking subsystem employs the SORT (Simple Online Real-Time Tracking) [35] algorithm to track and record the location and path of each detected object throughout the video. Additionally, this subsystem assigns unique IDs to the detections and generates a log of their trajectories. The mapping and visualization subsystem is responsible for mapping the obtained coordinates from the previous subsystems onto a 2D grid (top view of the field). This is accomplished through perspective transformation techniques, employing known markers as reference points.
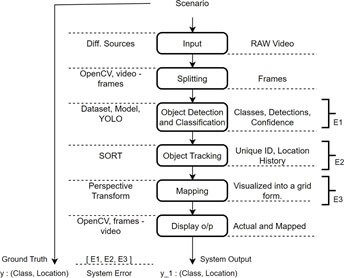
Fig. 1: Functional Operation of Adversary Target Detection
5. SUPPORTING T&E TRANSFORMATION
Various forms of data and models are generated throughout the systems engineering and acquisition process. These include simulation results, test data, ML training data, etc. In this paper, we refer to this collection of test data and simulation results as the “body of evidence” that can help establish trust in the ability of the AI/ML-based system to meet the mission objectives.
5.1 Create higher-level summaries of test data
The engineering team usually generates a significant amount of evidence during the development and calibration of the ML/AI models. For example, within the object detection subsystem of the illustrative example, testing is typically conducted by comparing the coordinates obtained for detected objects with ground truth data. The coordinates can be classified into three categories: correct coordinates, incorrect coordinates, and missing coordinates. Based on these findings, the system’s performance is evaluated using the F1 score, which provides a measure of the object detection performance. To enhance system robustness and minimize randomness, various parameters such as training size, batch size, and epochs (i.e., training sequences) are systematically varied, and their effects on the F1 score are observed.
Such evidence generated during the ML development process is large in quantity and is typically proprietary; therefore, it is not available to the DoD sponsor. The data can be summarized into higher-level data and visualization to facilitate learning from these initial development tests. For example, a heatmap can be generated for missing and incorrect coordinates (see Figure 2). The heatmap reveals any discernible patterns or relationships with other factors. The illustrated heatmap demonstrates that most incorrect or missing detections occur in this instance near the boundaries, as indicated by the white regions.
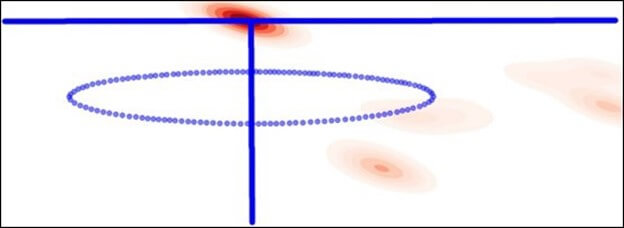 Fig. 2: Heatmap showing the missing and incorrect detection close
Fig. 2: Heatmap showing the missing and incorrect detection close
5.2 Document the details of the fidelities of models
As the design passes through the systems engineering process, models are constantly growing, changing, and being tested through various means. Surrogate models may be constructed for proof of concept during the early stages, then moved to more accurate representations of the operational use case as capabilities are proven. This is supported by the Joint Capabilities Integration and Development System (JCIDS) [36], implemented with the primary goal of evolving requirements as a program develops and information on the model is collected.
As described earlier, fidelity refers to the level of accuracy with which a system and its environment are modeled. Fidelities can range from different use cases of the AI systems to completely simulated operating environments for testing running off of oracles. Simulation is used to create test cases that may not occur during real-world testing [37] due to cost.
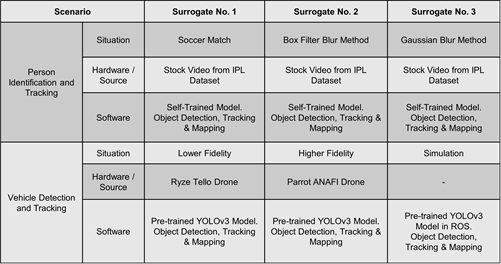
For example, different qualities of video feeds are considered for person identification and tracking. In Table 1, three fidelity levels are specified, namely original quality, blur quality, and Gaussian blur quality. The latter two fidelities are achieved by applying the respective functions from the OpenCV library [38] to the original raw video in the selected dataset. For the second surrogate scenario, vehicle detection and tracking, fidelities are obtained using drones with varying built and camera quality. The lower fidelity is attained using the Ryze Tello Drone, which possesses a lower camera resolution. In comparison, the higher fidelity is achieved using the Parrot to the boundaries ANAFI Drone, which offers higher resolution and improved viewing angles.
Table 1: Scenarios and Surrogates used for the given system
Developmental testing of models can be carried out using simulations. This is a common practice for autonomous vehicle development. Figure 3 illustrates the use of video games3 as simulations in conjunction with footage from a Warfield [39]. Comparisons between the performance of the ML models in these two scenarios lead to a better understanding of the system’s performance.

Fig. 3: Perception Performance Comparison Across Different Training Sets
5.3 Establish relationships among test data and models
There is a need to quantify (i) the difference between models, and (ii) the effect of the differences on the performance. New solutions have been created to ensure that simulation testing becomes more accessible for AI systems across a variety of industries [40, 41]. Research is continually growing on decreasing the gap between simulation and real-life without sacrificing computation speed [42]. Of recent papers on operating on multi-fidelity models, only a fraction discusses operating in a simulation as a fidelity [43, 44] to be leveraged. Models have also been built with data sets containing multiple fidelities [45, 46] or constructed from models that were trained separately on low and high-fidelity data [47].
5.4 Integrate evidence from white, gray, and black box tests
Testing can be classified as white-box, black-box, or gray-box, depending on the access to the system’s internals. White-box testing involves having complete knowledge of the system’s internal workings, allowing for a comprehensive assessment of individual components and their interactions. Black-box testing treats the system as an opaque entity, focusing on input-output correlations without detailed knowledge of internal mechanisms. Gray-box testing combines white-box and black-box testing elements, striking a balance between understanding internal workings and validating input-output relationships. These testing approaches can be applied in frameworks based on data accessibility. When full access to the system’s internal data is available, white-box testing can be utilized to thoroughly evaluate the system’s behavior. Black-box or gray-box testing may be more suitable in situations with limited data access. By incorporating these methodologies into the framework design, a more comprehensive evaluation of the system’s performance can be achieved, irrespective of the data accessibility constraints [48].
For example, the first surrogate training set has been created for a CNN model running off of the YOLO [49] architecture. The system is seen as a “white box”, as training data is known, inputs and outputs are known, and the size, shape, and parameters of the CNN created are all known to the research team. For the second surrogate, vehicle identification and tracking, a pre-trained version of YOLO running off the COCO [50] data set has been used. This would be a gray box as all images used to train the system are publicly available. However, the data set is so large that the research team does not have enough time to view each input.
5.5 Establish methods to integrate models/sources of information
Computational methods for multi-fidelity modeling enable the integration of models and data sources to obtain a holistic understanding of the system’s performance. Such methods for domain-specific problems have been developed for materials design where simulation models and experiments from different physical scales are integrated to predict the performance by leveraging the knowledge at quantum-, micro-, meso-, and continuum-scales. Domain-independent techniques for such integration leverage decision theory, Bayesian methods, information economics, sequential decision-making techniques, and optimal learning. There is a need for adaptation of such frameworks for AI/ML-based systems.
Conclusion
In summary, the rapidly advancing technologies of ML and AI will require new methods to test and evaluate AI-enabled systems adequately. It is important to acknowledge that each phase of testing (i.e., contractor, developmental, and operational) has varying levels of fidelity, all of which may not reflect the fidelity of actual operations in the field. New methods are needed to systematically and, without introducing biases, evaluate AI-enabled systems from a “body of evidence” that will grow and evolve across the acquisition life cycle. This paper identifies five key actions to support such analyses: (i) create and share higher-level summaries of test data generated throughout the development process, (ii) document the details of the fidelities of models generated, and the testing conditions, (iii) establish relationships among test data and models, (iv) integrate evidence from white, gray, and black box tests to generate a holistic understanding of the system behavior, and (v) establish computational methods to integrate models/sources of information. These steps are supported by current initiatives in the DoD to improve data discoverability and access while maintaining security and the emphasis on accelerating the analysis of test data.
Acknowledgments
This material is based upon work supported, in whole or in part, by the U.S. Department of Defense, Director, Operational Test and Evaluation (DOT&E) through the Office of the Assistant Secretary of Defense for Research and Engineering (ASD(R&E)) under Contract HQ003419D0003. The Systems Engineering Research Center (SERC) is a federally funded University-Affiliated Research Center managed by the Stevens Institute of Technology. Any views, opinions, findings conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the United States Department of Defense (specifically DOT&E and ASD(R&E)).
References
[1]L. Freeman, “Test and evaluation for artificial intelligence,” INSIGHT, vol. 23, No. 1, p. 27–30, Mar. 2020. https://doi.org/10.1002/inst.12281
[2]L. E. Lwakatare, A. Raj, I. Crnkovic, J. Bosch, and H. H. Olsson, “Large-scale machine learning systems in real-world industrial settings: A review of challenges and solutions,” Information and Software Technology, vol. 127, p. 106368, Nov. 2020.
[3]R. A. Kass, “Twenty-one parameters for rigorous, robust, and realistic operational testing,” ITEA Journal, vol. 36, pp. 121–138, 2015.
[4]J. Chandrasekaran, T. Cody, N. McCarthy, E. Lanus, and L. Freeman, “Test & evaluation best practices for machine learning- enabled systems,” arXiv preprint arXiv:2310.06800, 2023. https://doi.org/10.48550/arXiv.2310.06800
[5]Department of Defense, Defense Acquisition Guidebook. Defense Acquisition University, 2013. https://www.dote.osd.mil/Portals/97/docs/TEMPGuide/DefenseAcquisitionGuidebook.pdf
[6]E. Lanus, I. Hernandez, A. Dachowicz, L. J. Freeman, M. Grande, A. Lang, J. H. Panchal, A. Patrick, and S. Welch, “Test and evaluation framework for multi-agent systems of autonomous intelligent agents,” in 2021 16th International Conference of System of Systems Engineering (SoSE), pp. 203–209, 2021.
[7]D. Marijan and A. Gotlieb, “Software testing for machine learning,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, No. 9, pp. 13576–13582, Apr. 2020. https://doi.org/10.1609/aaai.v34i09.7084
[8]D. Doermann and D. Mihalcik, “Tools and techniques for video performances evaluation,” Proceedings – International Conference on Pattern Recognition, Barcelona, Spain, pp. 167-170 vol.4, 2000. https://doi.org/10.1109/ICPR.2000.902888
[9]X.-S. Hua, L. Wenyin, and Zhang H-J., “Automatic performance evaluation for video text detection,” Proceedings of Sixth International Conference on Document Analysis and Recognition, Seattle, WA, USA, 2001, pp. 545-550. https://doi.org/10.1109/ICDAR.2001.953848
[10]V. Mariano, J. Min, J.-H. Park, R. Kasturi, D. Mihalcik, H. Li, D. Doermann, and T. Drayer, “Performance evaluation of object detection algorithms,” 2002 International Conference on Pattern Recognition, Quebec City, QC, Canada, 2002, vol. 3, pp. 965-969. https://doi.org/10.1109/ICPR.2002.1048198
[11]L. Deng, “The MNIST database of handwritten digit images for machine learning research,” IEEE Signal Processing Magazine, vol. 29, no. 6, pp. 141–142, 2012. https://doi.org/10.1109/MSP.2012.2211477
[12]A. Krizhevsky, V. Nair, and G. Hinton, “CIFAR-10 (Canadian Institute for Advanced Research),” http://www.cs.toronto.edu/kriz/cifar.html
[13]A. Unwin and K. Kleinman, “The iris data set: In search of the source of virginica,” Significance, vol. 18, p. 26–29, Nov. 2021. https://doi.org/10.1111/1740-9713.01589
[14]B. Koch, E. Denton, A. Hanna, and J. G. Foster, “Reduced, reused and recycled: The life of a dataset in machine learning research,” 2021. https://arxiv.org/abs/2112.01716
[15]S. Razakarivony and F. Jurie, “Vehicle detection in aerial imagery: A small target detection benchmark,” Journal of Visual Communication and Image Representation, vol. 34, p. 187–203, Jan. 2016. https://doi.org/10.1016/j.jvcir.2015.11.002
[16]J. H. Jepsen, K. H. Terkildsen, A. Hasan, K. Jensen, and U. P. Schultz, “UAVAT Framework: UAV Auto Test Framework for Experimental Validation of Multirotor sUAS Using a Motion Capture System,” in 2021 International Conference on Unmanned Aircraft Systems (ICUAS), pp. 619–629, 2021. https://doi.org/10.1109/ICUAS51884.2021.9476699
[17]Lingg, M., Kushnier, T.J., Proenza, R., Paul, H., Grimes, B., Thompson, E., “Multi-level hardware-in-the-loop test API for hardware-software integration testing”, White Paper, 2002. https://www.arrayofengineers.com/post/white-paper-multi-level-hardware-in-the-loop-test-api-for-hardware-software-integration-testing
[18]K. Pei, Y. Cao, J. Yang, and S. Jana, “DeepXplore: automated whitebox testing of deep learning systems,” Communications of the ACM, vol. 62, No. 11, p. 137–145, October 2019. https://doi.org/10.1145/3361566
[19]Y. Tian, K. Pei, S. Jana, and B. Ray, “DeepTest: Automated Testing of Deep-Neural-Network-driven Autonomous Cars,” ICSE ’18: Proceedings of the 40th International Conference on Software Engineering May 2018, Pages 303–314. https://doi.org/10.1145/3180155.3180220
[20]Y. Abeysirigoonawardena, F. Shkurti, and G. Dudek, “Generating adversarial driving scenarios in high-fidelity simulators,” in 2019 International Conference on Robotics and Automation (ICRA), Montreal, Canada, May 20-24, pp. 8271–8277, 2019. https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8793740
[21]C. Torens, U. Durak, and J. C. Dauer, Guidelines and Regulatory Framework for Machine Learning in Aviation. https://arc.aiaa.org/doi/abs/10.2514/6.2022-1132
[22]European Union Aviation Safety Agency, “Artificial Intelligence Roadmap: A Human-centric Approach to AI in Aviation — EASA,” 2023. https://www.easa.europa.eu/en/domains/research-innovation/ai
[23]Underwriters’ Laboratories, UL 4600: Standard for Evaluation of Autonomous Products. Standard for safety, Underwriters Laboratories, 2020. https://ulse.org/ul-standards-engagement/autonomous-vehicle-technology
[24]“Standards Works – SAE International.” https://standardsworks.sae.org/standards-committees/g-34-artificial-intelligence-aviation
[25]“ISO 26262-1:2011.” https://www.iso.org/standard/43464.html
[26]H. Wang, X. Meng, Q. Tang, Y. Hao, Y. Luo, and J. Li, “Development and application of a standardized test set for an artificial intelligence medical device intended for the computer-aided diagnosis of diabetic retinopathy,” Journal of Healthcare Engineering, vol. 2023, p. 1–9, Feb. 2023. https://doi.org/10.1155/2023/7139560
[27]Office of the Under Secretary of Defense for Research and Engineering, “DoD Instruction 5000.89,” 2020 https://www.esd.whs.mil/Portals/54/Documents/DD/issuances/dodi/500089p.PDF
[28]M. A. Milley, “Army regulation 73-1 test and evaluation policy,” 06 2018. https://www.acqnotes.com/Attachments/Army
[29]J. D. Claxton, C. Cavoli, and C. Johnson, “Test and evaluation management guide, Fifth edition,” 2005. https://apps.dtic.mil/sti/pdfs/ADA436591.pdf
[30]“Army Publishing Directorate.” https://armypubs.army.mil/ProductMaps/PubForm/Details.aspx?PUB ID=1004352
[31]National Academies of Sciences, Engineering, and Medicine, “Testing, evaluating, and assessing artificial intelligence-enabled systems under operational conditions for the department of the air force,” Consensus Study Report, National Academies Press, 2023. https://nap.nationalacademies.org/catalog/27092/test-and-evaluation-challenges-in-artificial-intelligence-enabled-systems-for-the-department-of-the-air-force
[32]N. Guertin, DOT&E Strategy and Implementation Plan. Department of Defense, 2023. https://www.dote.osd.mil/News/News-Display/Article/3380429/dote-strategy-implementation-plan-2023/
[33]P. Wach, J. Krometis, A. Sonanis, D. Verma, J. Panchal, L. Freeman, and P. Beling, “Pairing Bayesian methods and systems theory to enable test and evaluation of learning-based systems,” INSIGHT, vol. 25, p. 65–70, Dec. 2022. https://doi.org/10.1002/inst.12414
[34]J. Redmon and A. Farhadi, “YOLOv3: An Incremental Improvement,” 04 2018. https://arxiv.org/abs/1804.02767[35]A. Bewley, Z. Ge, L. Ott, F. Ramos, and B. Upcroft, “Simple online and realtime tracking,” 2016. https://arxiv.org/abs/1602.00763
[36]M. A. Milley, “Manual for the operation of the joint capabilities integration and development system,” 08 2018. https://www.dau.edu/sites/default/files/2024-01/Manual%20-%20JCIDS%20Oct%202021.pdf
[37]A. Piazzoni, J. Cherian, J. Dauwels, and L.-P. Chau, “On the simulation of perception errors in autonomous vehicles,” 2023. https://arxiv.org/abs/2302.11919
[38]K. Pulli, A. Baksheev, K. Kornyakov, and V. Eruhimov, “Real-time computer vision with OpenCV,” Communications of the ACM, vol. 10, No 4, p. 40–56, 2012. https://doi.org/10.1145/2181796.2206309
[39]Fortitude, “Ukranian special forces engage Donbass militants forward post — thermal combat footage,” July 2021. https://www.youtube.com/watch?v=2Z7L1otTpk
[40]A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, “CARLA: An open urban driving simulator,” 2017. https://arxiv.org/abs/1711.03938
[41]V. S. R. Veeravasarapu, R. N. Hota, C. Rothkopf, and R. Visvanathan, “Simulations for validation of vision systems,” 2015. https://arxiv.org/abs/1512.01030
[42]J. A. Ferwerda, “Three varieties of realism in computer graphics,” in Human Vision and Electronic Imaging VIII (B. E. Rogowitz and T. N. Pappas, eds.), SPIE, June 2003. http://dx.doi.org/10.1117/12.473899
[43]M. G. Ferna´ndez-Godino, “Review of multi-fidelity models,” Advances in Computational Science and Engineering, 2023, 1(4): 351-400. https://doi.org/10.3934/acse.2023015
[44]E. Huang, J. Xu, S. Zhang, and C.-H. Chen, “Multi-fidelity model integration for engineering design,” Procedia Computer Science, vol. 44, p. 336–344, 2015. https://doi.org/10.1016/j.procs.2015.03.002
[45]J. Chen, Y. Gao, and Y. Liu, “Multi-fidelity data aggregation using convolutional neural networks,” Computer Methods in Applied Mechanics and Engineering, vol. 391, p. 114490, Mar. 2022. https://doi.org/10.1016/j.cma.2021.114490
[46]M. Motamed, “A multi-fidelity neural network surrogate sampling method for uncertainty quantification,” 2019. https://arxiv.org/abs/1909.01859
[47]S. Chen, Z. Jiang, S. Yang, D. W. Apley, and W. Chen, “Nonhierarchical multi-model fusion using spatial random processes,” International Journal for Numerical Methods in Engineering, vol. 106, p. 503–526, Sept. 2015. https://doi.org/10.1002/nme.5123
[48]V. Riccio, G. Jahangirova, A. Stocco, N. Humbatova, M. Weiss, and P. Tonella, “Testing machine learning based systems: a systematic mapping,” Empirical Software Engineering, vol. 25, p. 5193–5254, Sept. 2020. https://doi.org/10.1007/s10664-020-09881-0
[49]J. Terven and D. Cordova-Esparza, “A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS,” 2023. https://doi.org/10.48550/arXiv.2304.00501
[50]T.-Y. Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P. Perona, D. Ramanan, C. L. Zitnick, and P. Dolla´r, “Microsoft COCO: Common Objects in Context,” 2014. https://doi.org/10.48550/arXiv.1405.0312
Author Biographies
Robert Seif is a Master’s student in Mechanical Engineering at Purdue University. He works on creating methods to safely test and evaluate ground-breaking AI systems to ensure best use and practice. Outside of his work with Purdue University, he is a co-founder of an AI-powered lead generation company for the real estate industry.
Atharva Sonanis received his Master of Science degree in Mechanical Engineering from Purdue University. He is passionate about the intersection of robotics, computer vision, and automation. He strives to develop innovative solutions that can revolutionize industries and improve lives.
Dr. Laura Freeman is the Deputy Director of the Virginia Tech National Security Institute, and is the Assistant Dean of Research for the College of Science. Dr. Freeman previously served as the assistant director of the Operational Evaluation Division at the Institute for Defense Analyses. She served as the acting senior technical advisor to the Director of Operational Test and Evaluation in 2018. She has a B.S. in Aerospace Engineering, M.S. in Statistics and Ph.D. in Statistics, all from Virginia Tech.
Dr. Kristen Alexander is the Chief Learning and Artificial Intelligence Officer at DOT&E and focuses on adequate testing of AI-enabled systems and developing curriculum to support the T&E workforce. Prior to that, she served as the Technical Advisor for Deputy Director, Land and Expeditionary Warfare at DOT&E. Dr. Alexander received her Ph.D. from Carnegie Mellon University in Chemical Engineering and is the recipient of the Secretary of Defense Medal for Exceptional Civilian Service.
Dr. Jitesh H. Panchal is a Professor and Associate Head of Mechanical Engineering at Purdue University. Dr. Panchal’s research interests are in design at the interface of social and physical phenomena, computational methods and tools for digital engineering, and secure design and manufacturing.
